您现在的位置:首页
--> 算法




K-Means是一个超级简单的聚类方法,说他简单,主要原因是使用它时只需设置一个K值(设置需要将数据聚成几类)。但问题是,有时候我们拿到的数据根本不知道要分为几类,对于二维的数据,我们还能通过肉眼观察法进行确定,超过二维的数据怎么办?今天就一起来学习下。




在K-Means算法中,最终的聚类效果受初始的聚类中心的影响,K-Means++算法的提出,为选择较好的初始聚类中心提供了依据,但是算法中,聚类的类别个数k仍需事先制定,对于类别个数事先未知的数据集,K-Means和K-Means++将很难对其精确求解,对此,有一些改进的算法被提出来处理聚类个数k未知的情形。Mean Shift算法,又被称为均值漂移算法,与K-Means算法一样,都是基于聚类中心的聚类算法,不同的是,Mean Shift算法不需要事先制定类别个数k。
Mean Shift的概念最早是由Fukunage在1975年提出的,在后来由Yizong Cheng对其进行扩充,主要提出了两点的改进:定义了核函数,增加了权重系数。核函数的定义使得偏移值对偏移向量的贡献随之样本与被偏移点的距离的不同而不同。权重系数使得不同样本的权重不同。
Mean Shift算法在很多领域都有成功应用,例如图像平滑、图像分割、物体跟踪等,这些属于人工智能里面模式识别或计算机视觉的部分;另外也包括常规的聚类应用。
其实老早就像写一点这个话题。几乎我见过的所有大型系统中,都需要一个唯一ID的生成逻辑。别看小小的ID,需求和场景还挺多:
这个ID多数为数字,但有时候是数字字母的组合;
可能随机,也可能要求随时间严格递增;
有时ID的长度和组成并不重要,有时候却要求它严格遵循规则,或者考虑可读性而要求长度越短越好;
某些系统要求ID可以预期,某些系统却要求ID随机性强,无法猜测(例如避免爬虫等等原因)。
独立的生成服务
比如数据库。最常见的一种,也是应用最多的一种,就是利用数据库的自增长序列。比如Oracle中的sequence的nextVal。有多台application的host,但是只有一个数据库。本质上这是耍了个小赖皮,把某分布式系统唯一ID的生成逻辑寄托到一个特定的数据库上,于是分布式系统存在中心节点了。
Paradox 是我很喜欢的一个游戏公司,在所谓 P 社 5 萌中,十字军之王和钢铁雄心都只有浅尝,但在维多利亚和群星上均投入了大量时间和精力。
这些游戏基于同一套引擎,所以数据文件格式也是共通的。P 社开放了 Mod ,允许玩家来修改游戏,所以数据文件都是明文文本存放在文件系统中,这给了我们一个极好的学习机会:对于游戏从业者,我很有兴趣看看成熟引擎是如何管理游戏数据和游戏逻辑的。
据我所接触到的国内游戏公司,包括我们自己公司在内,游戏数据大都是基于 excel 这种二维表来表达的。我把它称为 csv 模式。这种模式的特点是,基础数据结构基于若干张二维表,每张表有不确定的行数,但每行有固定了列数。用它做基础数据结构的缺陷是很明显的,比如它很难表达树状层级结构。这往往就依赖做一个中间层,规范一些使用格式,在其上模拟出复杂数据结构。



面试也是一门学问,在面试之前做好充分的准备则是成功的必须条件,而程序员在代码面试时,常会遇到编写算法的相关问题,比如排序、二叉树遍历等等。
在程序员的职业生涯中,算法亦算是一门基础课程,尤其是在面试的时候,很多公司都会让程序员编写一些算法实例,例如快速排序、二叉树查找等等。
本文总结了程序员在代码面试中最常遇到的10大算法类型,想要真正了解这些算法的原理,还需程序员们花些功夫。
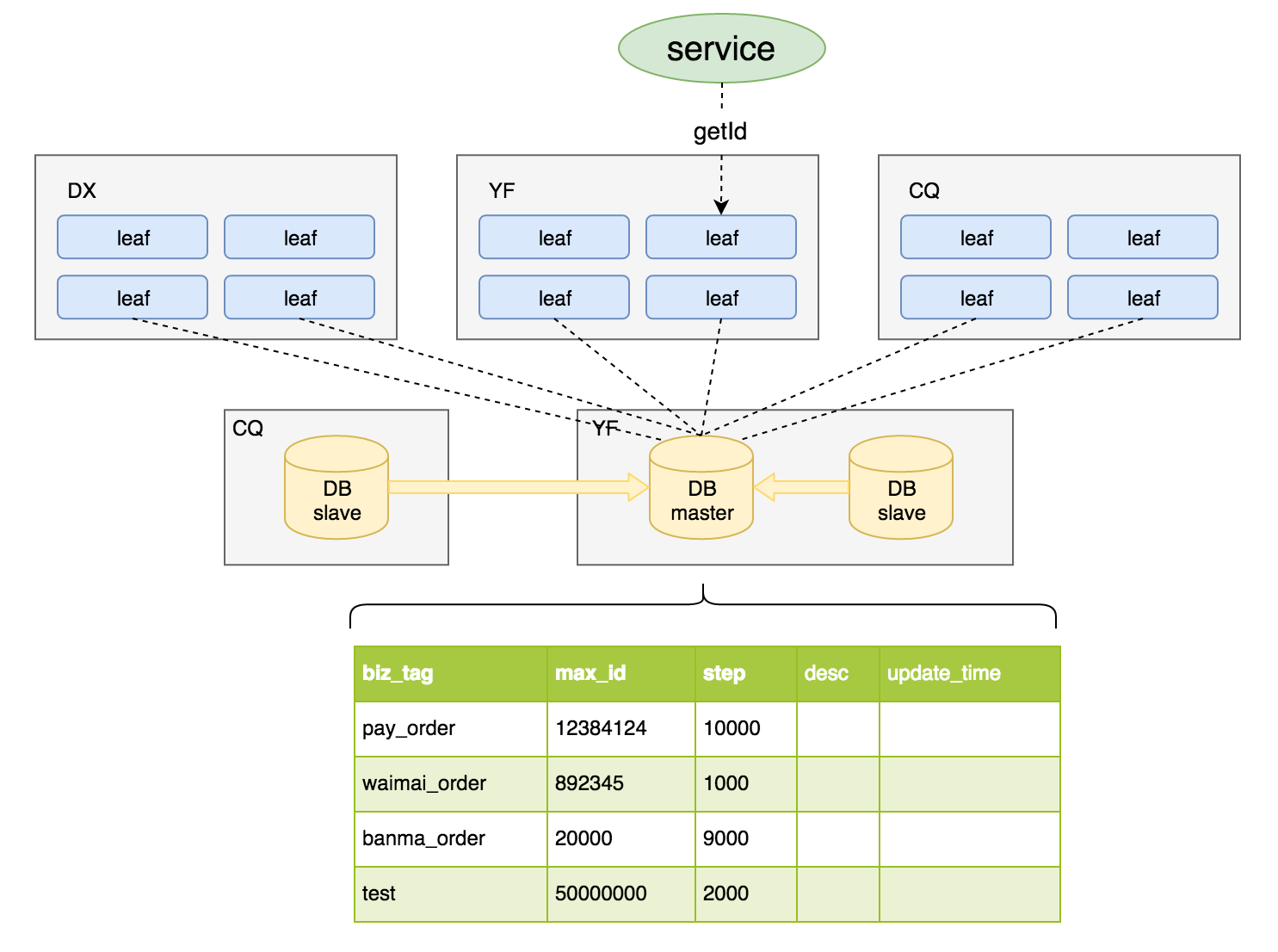
• 订单号的生成规则
今天有同学跟我讨论了一下最近发现的一个 bug ,我觉得挺有意思的。
需求是这样的:
我们的系统中,有一些数据是从外存(数据库)加载进来的,由于性能考虑,并不需要每次修改这些数据就写回外存。希望在数据变冷后,定期落地即可。
典型的场景是一个 cache 模块,cache 的是一些玩家的业务数据,可以通过 uuid 从数据库索引到。一旦业务需要访问玩家数据,cache 模块会从数据库加载对应数据,然后把数据表交出去。当业务再次需要这些数据的时候,cache 模块一旦发现数据存在于 cache 中,就直接交给玩家。
cache 模块还希望在数据很久没有被业务访问时,将这些数据写回数据库。
我们的系统是基于 lua 构建的,数据 cache 模块和修改这些数据的逻辑在同一个 vm 里。难点在于,修改数据的业务逻辑是可以长期持有数据的,cache 模块需要正确感知这点。
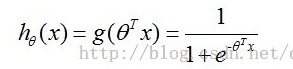
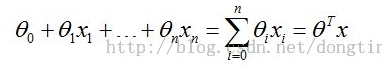
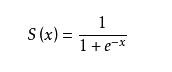
作为设计理想,玩家不会成为一个整体,他们之间有竞争。更高的名次有更高的奖励,所以不会轻易降分。
但事实上,由于玩家可以充分的沟通相互信任,不会陷入囚徒困境。竞争多花的钱而获得的高名次奖励,远远比不上交替名次而获得的系统额外发放。另外,在原来的低名次段,原本没有名次奖励的位置,也可以通过操纵排名而获益。

• 跳跃表




今天,有个同学向我咨询大数据的一些面试题,其中一类比较有代表性比如判断是否在集合内,比如10个url,判断一个url是否在集合内,还比如有个1~100万个连续无序数字,随机取出里面的N个,求这N个数字等等。这类问题都需要一个大的数据集合,而且每个数据单元都很小,比如一个int 。很大程度上,这类问题可以用Bitmap或者Bloomfilter来做,基本思想就是开辟一块大内存,然后利用一个byte里的8个bit来实现按位标记元素。因为地址空间都是连续的,所以查找都是O(1)的。这里需要说的是,BloomFilter判断属不属于集合,在理论上是存在误判的,如果要求数据100%正确,则不要使用BloomFilter。


Trie树,即字典树,又称单词查找树或键树,是一种树形结构。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是最大限度地减少无谓的字符串比较,查询效率比较高。
Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
这几天 AlphaGo 4:1 战胜了李世石,围棋积分网站 给了 AlphaGo 一个世界排名。在 3:1 的时候是世界第四,4:1 后上升到了世界第二。
我很好奇这个网站是如何给棋手打分的,便顺着链接指引翻了下 wikipedia 读了几篇 paper 。
下面是我的一些理解,由于我的数学基本功不太扎实,难免有错误,所以有兴趣的同学最好自己读论文 。
有这样一道算法题:
给定一个能够生成均匀1~5随机枚举数的函数,请设计一个能够生成均匀1~7随机枚举数的函数。
就是说,有一个生成随机数的函数rand5,可能返回1、2、3、4、5这5个枚举值,其中每个值被返回的概率都是严格的1/5,现在需要设计一个类似的随机数函数rand7,可能返回1、2、3、4、5、6、7这几个枚举值,每个值被返回的概率都是严格的1/7。
• 缓存算法–LRU
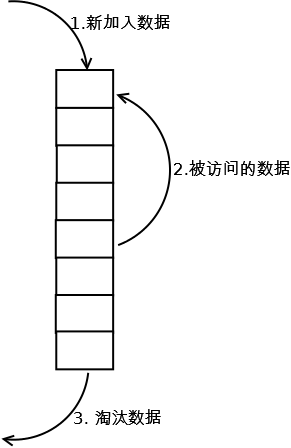
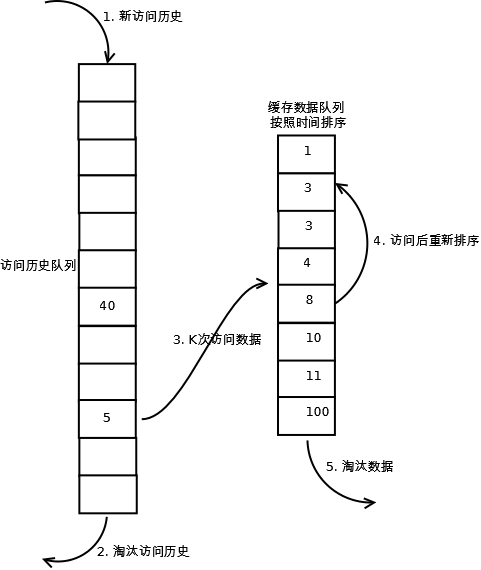
LRU是Least Recently Used 的缩写,翻译过来就是“最近最少使用”,也就是说,LRU缓存把最近最少使用的数据移除,让给最新读取的数据。而往往最常读取的,也是读取次数最多的,所以,利用LRU缓存,我们能够提高系统的performance.
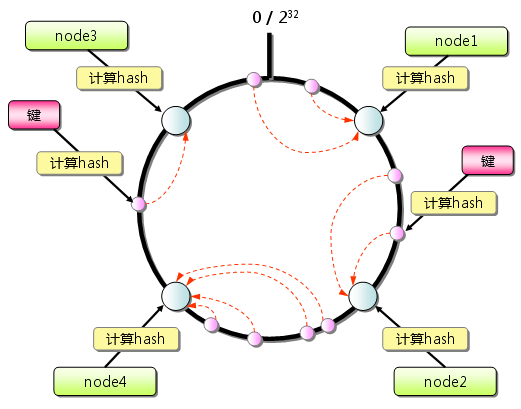
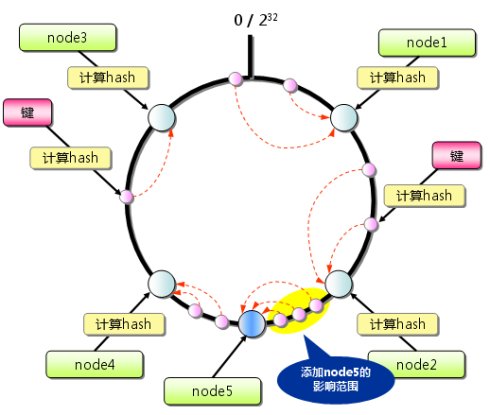

一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
1、平衡性(Balance);
2、单调性(Monotonicity);
3、分散性(Spread);
4、负载(Load);
低级程序员认为自己与高级程序员的区别, 主要是高级程序员任何功能都能编码实现, 编码速度快, 代码无 bug. 正如一惯的那样, 低级程序员之所以低级, 正是因为他们勉强能看到(或者根本看不到)事物的表象而看不到本质. 所以, 低级程序员总结出的一切东西, 你都可以大胆的忽略.
所以, 我们来听听高级程序认为自己与低级程序员的区别是什么. 高级程序员之所以高级, 在于他们认识到代码 bug 是不可避免的, 有千万种理由可以导致 bug, 但他们可以在设计和逻辑上保证(追求)滴水不漏, 并用逻辑的百分之百准确性还减少代码 bug. 没错, 严谨的逻辑能力是高级程序员区别于低级程序员的最主要原因.
本文大致介绍了哈希的几种用途,有可能是大家熟知的用途,也有可能是巧用,总之就是说了为什么我要用哈希。
在编程中,无论是实际用途还是自己玩玩的题目,多动动脑子就会出来一些“奇技淫巧”。哈希也好,别的东西也罢,反正都是为了解决问题的——千万别因为实际开发中通常性的“并没有什么卵用”而去忽视它们,虽然哈希已经是够常用的了。

近3天十大热文
-
 [81] Go Reflect 性能
[81] Go Reflect 性能 -
[15] 我的git笔记
-
[12] 公钥私钥加密解密数字证书数字签名详解
-
[12] osx平台上lol英雄联盟launcher启
-
[11] 浅谈Web安全验证码
-
[11] iTerm2 (Mac Terminal)
-
[11] 系统工程师的自我修养- sed篇
-
[11] iOS可视化编程 Tips 之“无需代码设置
-
[11] 正态分布的前世今生(一)
-
[11] 基于HTTP缓存轻松实现客户端应用的离线支持
赞助商广告
