一个冷门的速查日历方法
终端中的 `cal` 命令是一款轻量高效的日历查询工具,特别适合开发者在编码过程中快速查看日期。其核心优势在于调用速度快,作为集成开发环境(如 VSCodium)终端面板的一部分,输入命令即可即时获取日历视图,无需切换至图形化应用。输出为纯文本格式,便于直接复制到笔记中进行后续整理或标注,契合偏好命令行操作的极简风格。 该命令提供多种参数以满足不同场景需求:通过 `cal 2025` 可直接查看指定年份的全年日历;`cal -m 3` 用于显示特定月份;`cal -3` 会同时呈现当前月及其前后月份,便于进行日期规划。进阶用法如 `ncal -w` 能够以每周一列的布局显示日历并附带周数,适合进行周期性任务管理。更多选项可通过 `man cal` 手册查阅,该命令历史悠久,自1971年首次出现在AT&T UNIX系统中,其稳定性和简洁性经受了长期考验。
Git 将某个文件恢复到其他分支的状态
Git 中恢复文件到其他分支状态有两种常用命令。假设当前在 main 分支,希望将 path/to/config.yaml 文件恢复到 dev 分支的状态,可以使用 git checkout dev -- path/to/config.yaml,或 git restore --source=dev -- path/to/config.yaml。这两种方法本质上相同,都通过指定源分支和文件路径,将目标文件从 dev 分支覆盖到当前分支,而不影响其他文件或提交历史。这种操作适用于版本控制中的局部文件恢复场景,例如在合并前同步配置或修复特定分支的代码差异。git checkout 是较旧的命令,而 git restore 是更现代且语义明确的替代,推荐使用后者以提高可读性。实际执行时,Git 会从 dev 分支提取文件内容,并更新当前工作区的对应文件,无需切换分支或创建额外提交。这两种方式都强调了分支独立性和文件级操作的灵活性,有助于维护代码库的一致性和可追溯性。
Stack Overflow: When We Stop Asking
Stack Overflow问题数量从2014年高峰的月均20万急剧下降到2026年不足3千,AI是直接冲击,但更早源于平台管理问题:为控制规模而过度关闭无法立即回答的问题,强调内容质量却导致社区封闭,新手难以提问且易受挫。AI虽提供快速答案,但生成的代码存在缺陷:Cornell研究表明AI代码更简单重复、有维护问题,MIT研究指出AI缺乏人类工程师
Star Trek : Captain's Chair 初体验
《星际迷航:船长之椅》是一款2025年发布的重度卡牌构筑桌游,规则复杂(BGG权重达4.06)。游戏核心在于动态管理卡组,通过LOG(永久移除)、deploy(部署至桌面)、beam(临时传送至飞船或星球)等多种机制进行灵活的卡组瘦身,显著提升了操作确定性。每张卡牌设计为一卡多用,且玩家在回合结束时可保留手牌、弃牌堆抽牌、新牌入堆位置可选等方式,深度调控牌堆轮转与升级节奏。游戏为每个舰长设计了差异化的初始牌组与固定补充卡堆,市场获取也改为通过特定行动卡实现。单人模式提供无干扰教学、对抗自动化Bot的不对称对战,以及可连续进行5-10局的长期升级“五年计划”。电子模拟版虽便捷,但实体版在触感、操作及反悔便利性上更具优势。作者学习过程中尝试使用AI(如Gemini)辅助理解规则,但AI对细节信息的处理常出现错误和“幻觉”,反映出在专业、小众领域辨别LLM信息价值的重要性。
读《控糖革命》
《控糖革命》一书挑战了传统的热量计算观念,指出维持健康的关键在于控制“血糖峰值”而非仅仅关注卡路里。血糖剧烈波动会引发氧化应激和糖化反应,损害细胞并加速衰老。尤其值得注意的是果糖,它无法像葡萄糖一样被储存,而是直接转化为脂肪,这也是甜食更易致胖的重要原因。 书中提出了九项实操技巧来平滑血糖曲线,其核心策略在于调整进食顺序:优先摄入纤维(蔬菜),接着是蛋白质和脂肪,最后才食用淀粉或糖。纤维能在肠道内形成缓冲层,有效减缓糖分吸收。其他实用方法包括:利用餐前蔬菜建立纤维屏障、警惕代糖的潜在误导、选择含蛋白质与纤维的早餐、避免单独食用甜点、餐前饮用醋或油醋汁,以及餐后进行轻微活动。这些方法旨在通过尊重代谢规律,而非极端节食,来自然改善精力、皮肤状态与身材管理。
Use Obsidian Sync on Desktop without Installing Obsidian
作者在使用Obsidian Sync时面临一个问题:Obsidian GUI是一个基于Electron的重型应用,运行桌面端同步时占用资源多,且一旦关闭同步就会中断。为解决此问题,作者采用了Obsidian发布的headless同步终端客户端obsidian-headless。该客户端通过CLI命令(如ob --continuous)实现笔记文件夹的实时同步,无需运行GUI应用。具体配置步骤包括:使用npm全局安装obsidian-headless,通过ob login和ob sync-setup
我让 Linux REAPER 实现了输入法的功能
Linux REAPER 长期缺乏输入法支持,作者自2017年起持续尝试解决这一问题,早期仅能通过复制粘贴或第三方输入框输入中文。2022年,作者在Fcitx输入法框架的讨论组获得开发者csslayer指导,明确了通过修改REAPER开源图形库SWELL来实现输入法功能的方向。这一突破得益于输入法框架的技术支持和Steam在Linux平台解决类似问题的启示。 实现方法基于编译或替换SWELL库文件。用户需先确保REAPER能显示CJK字符(通过fontconfig配置)并设置正确的输入法环境变量。安装可选择下载预编译的libSwell.so文件替换原有文件,或从源码编译,编译时必须启用SWELL_SUPPORT_IM=1选项,并配合SWELL_SUPPORT_GTK=1。该方案为Linux REAPER提供了基本的中文输入能力。 已知问题包括窗口重启后输入法候选框位置异常(如Media Explorer窗口未关闭时)以及不同DPI下候选框位置适配问题。作者建议手动调整编译参数以优化显示。该项目解决了Linux REAPER用户的中文输入需求,但仍存在部分交互细节待改进。
SetWindowText 引起的死锁
在基于ltask多线程框架的游戏开发中,使用sokol_app封装窗口时遇到了启动阶段偶发黑屏的问题。经排查,死锁源于跨线程调用SetWindowTextW修改窗口标题。由于该API内部通过SendMessageW投递WM_SETTEXT消息,要求窗口线程处理完毕才能返回,而窗口线程当时正阻塞在另一个同步锁上,形成循环等待。 Windows消息机制要求通过SendMessageW发送涉及字符串生命周期管理的系统消息,因此不能简单改用PostWindowTextW避免阻塞。最终解决方案是在ltask框架内创建一个独立服务来执行SetWindowTextW,通过服务间异步消息传递修改标题指令,从而避免阻塞主帧处理流程。这一案例揭示了多线程环境下GUI消息循环与任务调度器交互时的典型死锁陷阱,关键在于理解Windows线程消息队列的同步特性,并设计解耦的线程通信机制。
编写游戏程序的一些启示
在制作《Deep Future》桌游电子版的过程中,作者通过实践深入探讨了游戏程序开发的多个核心问题。他选择基于自研引擎进行开发,旨在理解游戏玩法设计与交互实现的难点,而非追求性能优化。在渲染架构上,他经历了从纯立即模式向混合模式的演进:保留模式用于管理如HUD布局和文本排版等静态层次结构,而立即模式则用于实现动态对象的灵活渲染。针对卡牌游戏特有的复杂图文混排需求,他借鉴了CSS布局思想并集成了Yoga库,同时通过自定义富文本协议解决了本地化与文本拼接的难题。 为分离游戏逻辑与视觉表现,作者引入了基于协程的状态机模型,以自然的时间序列模拟卡牌动画等流程。在交互管理上,他设计了兼顾立即模式风格的焦点轮询机制,通过平坦化的“区域”和“按钮”集合简化了事件处理。这些实践表明,游戏开发中合理的架构分层与状态管理是应对复杂性的关键,而持续的小幅迭代和反思比追求完美方案更能有效推动项目进展。
在 Lua 中定义类型的简单方法
文章以教程形式探讨了在Lua中定义类型的简洁方法,重点介绍了从基础到进阶的实现策略。首先,作者展示了通过table和元表设置来创建类型的基本方式,这种方法依赖Lua模块机制,适合快速定义独立类型。随后,文章深入讨论了封装class模块的高级方案,通过统一管理类型定义和实例化,提供类型名查找功能,增强了代码组织性。内容核心转向
实用软件项目管理最佳实践
本文针对小型团队在软件项目中面临的交付延迟、需求变更与协作低效等问题,提出了一套注重实操的迭代管理方法。其核心在于建立固定产研节奏、标准化交付物与高频异步协作机制。 在节奏管理上,采用固定的短周期迭代(推荐双周),通过冲刺模式强制需求拆解与周期性交付,避免长期封闭开发风险。设立迭代经理角色负责排期与协调,并通过轮值促进理解。同时,利用公式估算工作量,并强制将大型需求拆分为“天”或“小时”级别的小任务。 在交接物方面,强调“写下来”以对抗软件的抽象性,要求为每个环节定义清晰的输入输出标准。例如使用结构化的需求清单与需求文档明确意图,用简洁的Release Note与持续更新的产品手册同步信息,所有文档力求简明。 在协作上,倡导“异步为主、同步为辅”。通过在线看板实现任务与风险的全局可视化,并将同步沟通压缩至必要的方案评审会与每日站会。会议需有明确结论与行动项,并全量同步至协作平台,以最大化建设性工作时间。
我的 CodeReview 实战经验
背景
Code Review 是大家日常开发过程中很常见的流程,当然也不排除一些团队为了快速上线,只要功能测试没问题就直接省去了 Code Review。
我个人觉得再忙的团队 Code Review 还是很有必要的(甚至可以事后再 Review),好处很多:
- 跳出个人开发的思维误区,更容易发现问题
- 增进团队交流,提高整体的技术氛围
- 团队水平检测器,不管是审核者还是被审核的,review 几次后大概就知道是什么水平了
通常 Code Review 有两种场景,一种是公司内部,还有就是开源社区。
开源社区
先说开源社区,最近也在做 cim 项目里做 Review,同时也在 Pulsar、OpenTelemetry、StarRocks 这些项目里做过 Reviewer。
以下是一些我参与 Code Review 的一些经验:
先提 issue
在提交 PR 进行 Code Review 之前最好先提交一个 issue 和社区讨论下,你的这个改动社区是否接受。
我见过一些事前没有提前沟通,然后提交了一个很复杂的 PR,会导致维护者很难 Review,同时也会打击参与者的积极性。
所以强烈建议一些复杂的修改一定先要提前和社区沟通,除非这是一些十拿九稳的问题。
个人 CI
一些大型项目往往都有完善的 CI 流程来保证代码质量,通常都有以下的校验:
- 各种测试流程(单元测试、集成测试)
- 代码 Code Style 检测
- 安全、依赖检测等
如果一个 PR 连 CI 都没跑过,其实也没有提前 Review 的必要了,所以在提 PR 之前都建议先在自己的 repo 里将主要的 CI 都跑过再提交 PR。
这个在 Pulsar 的官方贡献流程里也有单独提到。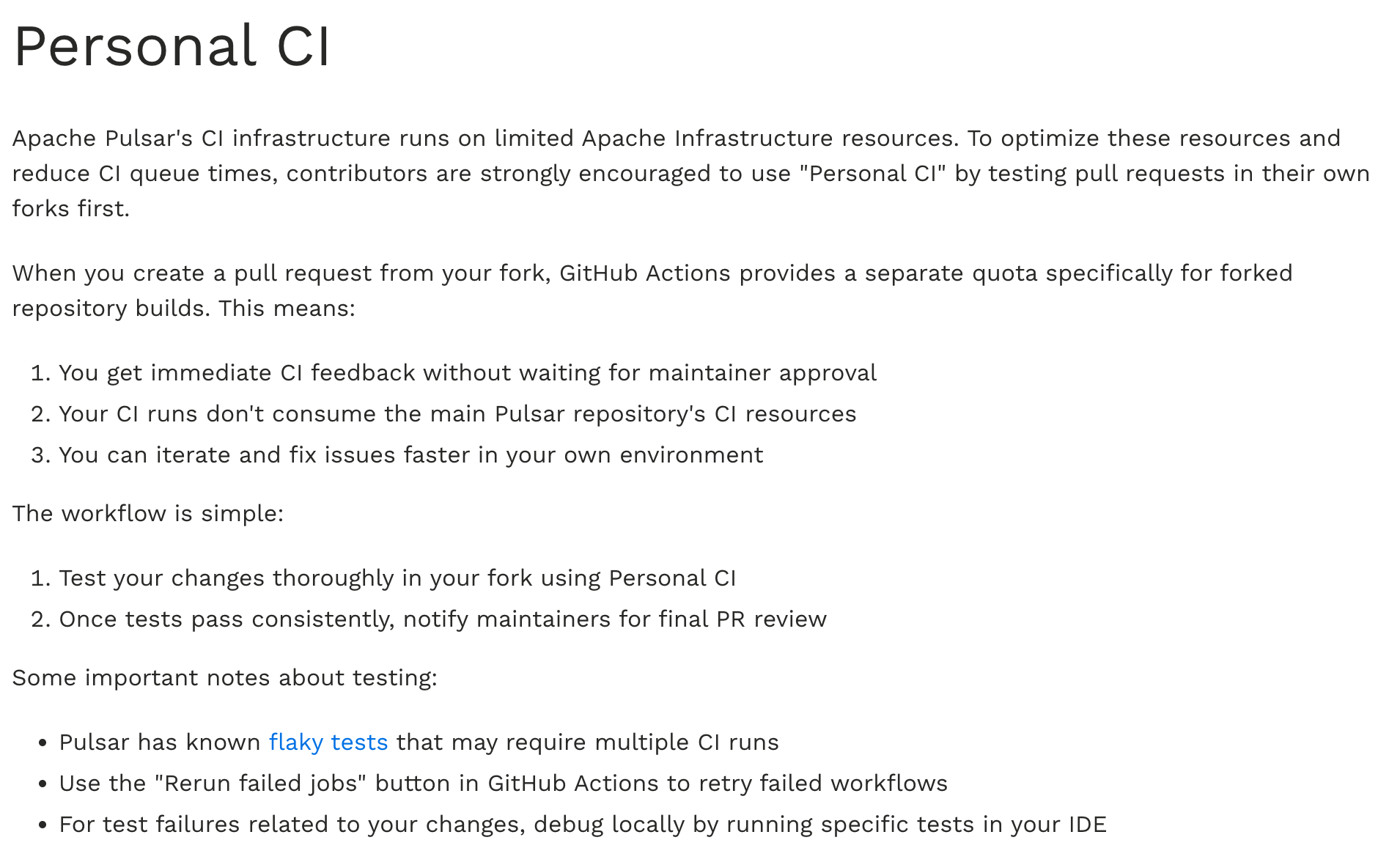
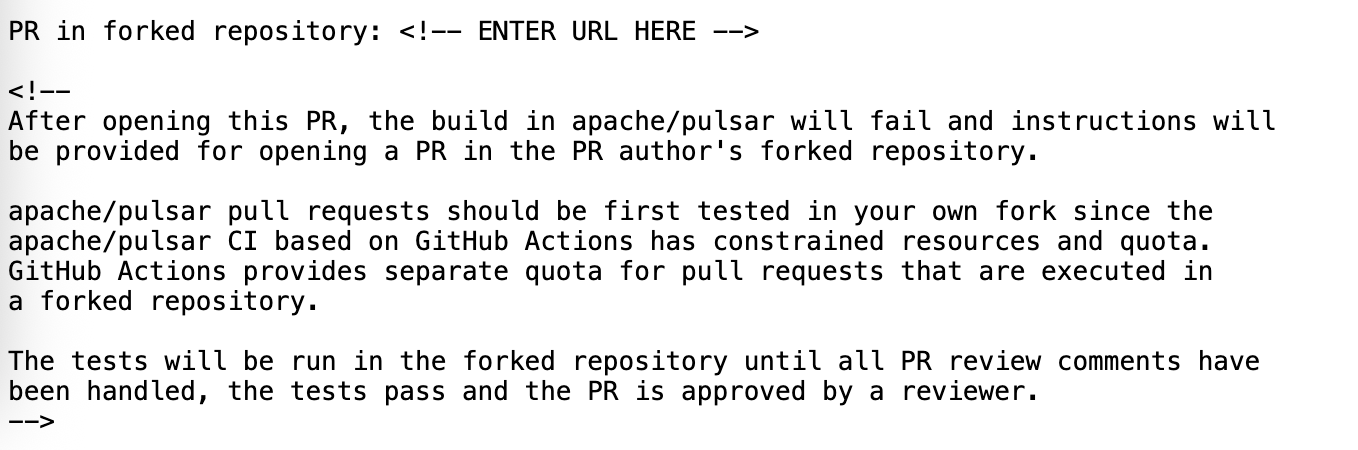
同时在 PR 模板里也有提到,建议先在自己的 fork 的 repo 里完成 CI 之后再提交到 upstream。
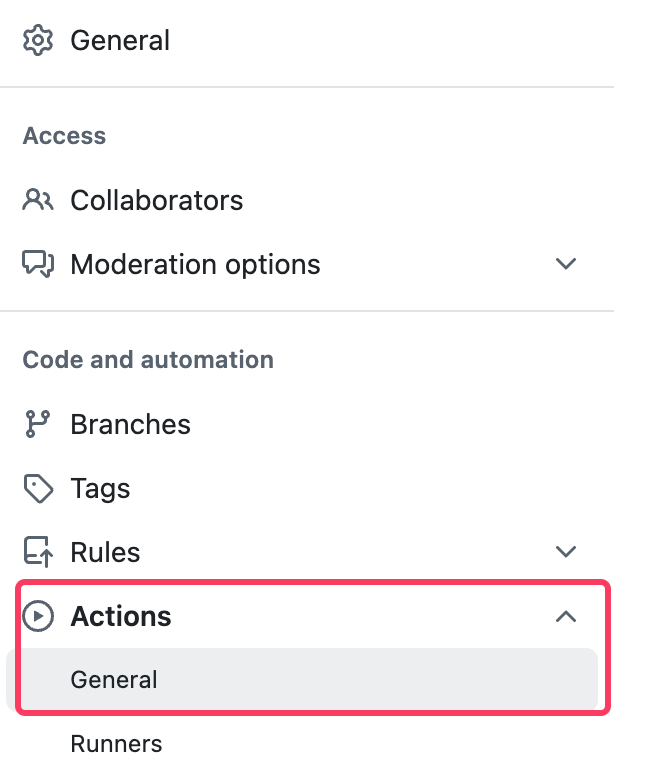
这个其实也很简单,我们只要给自己的 repo 提交一个 PR,然后在 repo 设置中开启 Action,之后就会触发 CI 了。
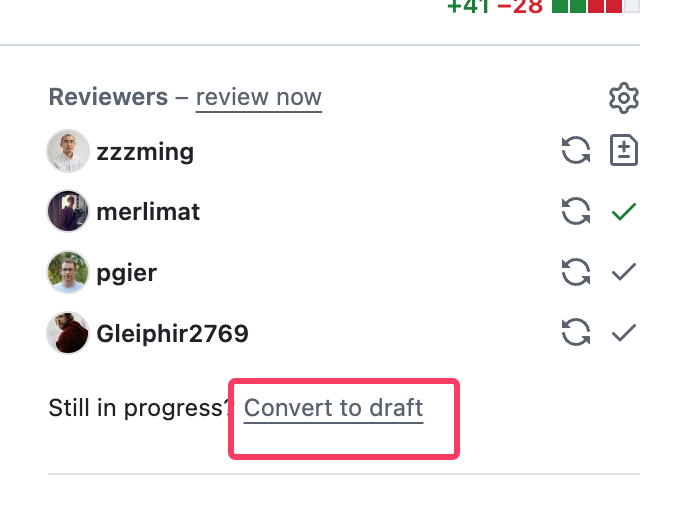
如果自己的 PR 还需要频繁的提交修改,那建议可以先修改为 draft,这样可以提醒维护者稍后再做 Review。
同时也不建议提交一个过大的 PR,尽量控制在 500 行改动以内,这样才方便 Review。
Review 代码

Github 有提供代码对比页面,但也只是简单的代码高亮,没法像 IDE 这样提供函数跳转等功能。

所以对于 Reviewer 来说,最好是在本地 IDE 中添加 PR 的 repo,这样就可以直接切换到 PR 的分支,然后再本地跟代码,也更好调试。
有相关的修改建议可以直接在 github 页面上进行评论,这样两者结合起来 Review,效率会更高。
Review 代码其实不比写代码轻松,所以对免费帮你做 Review 的要多保持一些瑞思拜。
AI Review
现在 Github 已经支持 copilot 自动 Review 了,它可以帮我们总结变更,同时对一些参加的错误提供修改建议。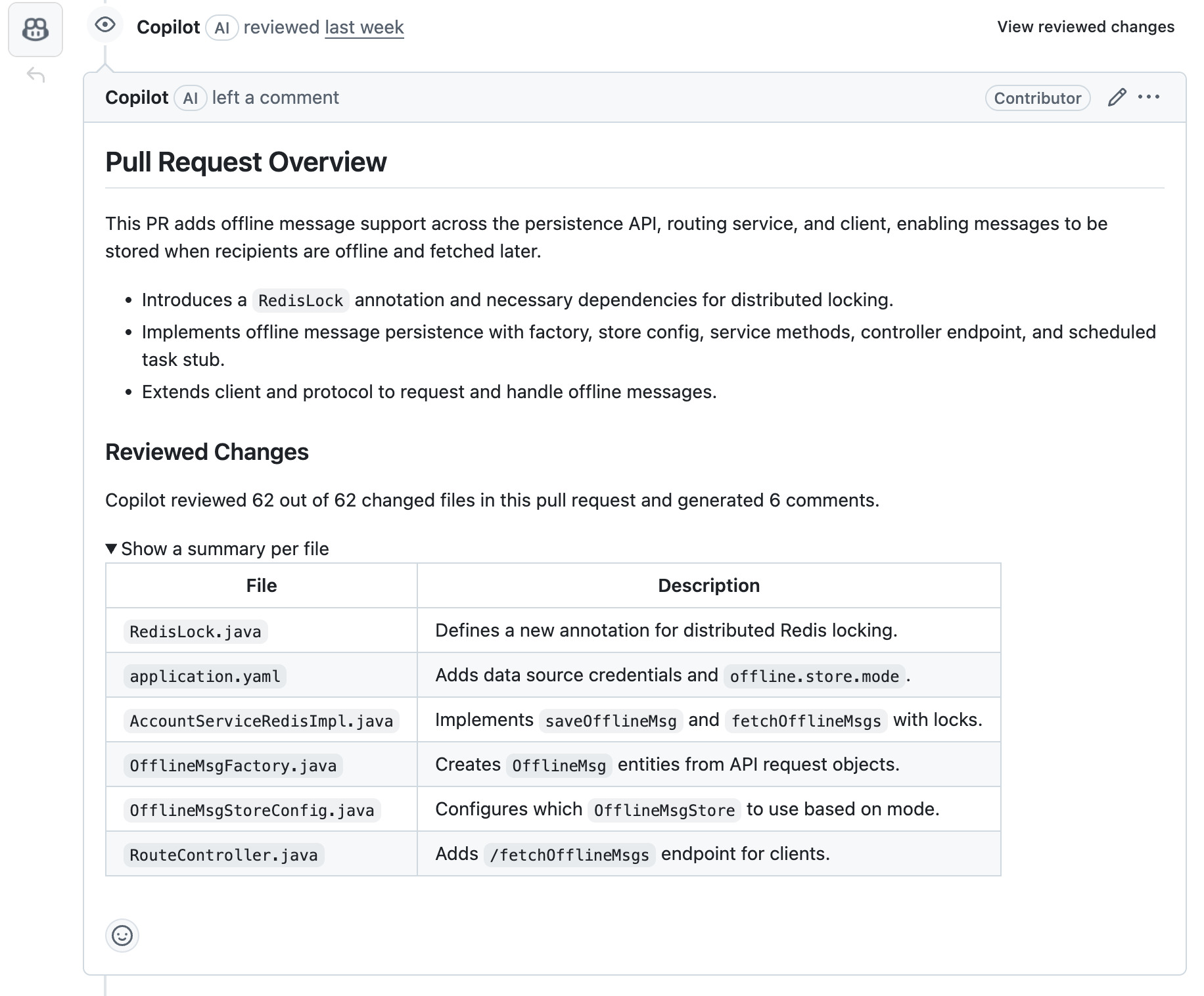
使用它还是可以帮我们省不少事情,推荐开启。
企业内部
在企业内部做 Code Review 流程上要简单许多,毕竟沟通成本要低一些,往往都是达成一致之后才会开始开发,所以重点就是 Review 的过程了。
既然是在公司内部,那就要发挥线下沟通的优势了;当然在开始前还是建议在内部的代码工具里比如说 gitlab 中提交一个 MR,先让参会人员都提前看看大概修改了哪些内容,最好是提前在 gitlab 中评论,带着问题开会讨论。
实际 Review 过程应该尽量关注业务逻辑与设计,而不是代码风格、格式等细枝末节的问题。
提出修改意见的时候也要对事不对人,我见过好几次在 Review 现场吵起来的场景,就是代入了一些主观情绪,被 Review 的觉得自己能力被质疑,从而产生了一些冲突。
Code Review 做得好的话整个团队都会一起进步,对个人来说参与一些优质开源项目的 Code Review 也会学到很多东西。
写代码与做菜
将编程中的模块化思想应用于烹饪,能有效提升学习效率。烹饪可拆解为预处理、烹制与收尾三个核心阶段,每个阶段包含若干可复用的具体操作模块。例如,无论是清蒸鱼还是红烧鱼,其预处理步骤(如去腥、改刀)高度相似,掌握后便可迁移至其他鱼类料理。类似地,红烧技法在鱼与肉等不同食材间也可通用,仅需调整调料与时长。这种阶段划分与模块复用的方式,让学习者能清晰定位自身薄弱环节,并通过组合已有模块来尝试新菜品。 进一步看,烹饪具体步骤还可借鉴面向对象编程的接口概念。例如,“上色”这一工序可通过炒糖色或使用老抽等多种实现方式完成,选择者可依据熟练度灵活取舍,体现“完成优于完美”的实践原则。对于不熟悉的环节,如食材初加工,则可类比服务化思想,通过采购半成品或外包完成。掌握常用模块、灵活组合阶段、善用外部服务,这三者结合能够降低烹饪门槛,逐步积累实践信心。文章最后以“火候”与“功夫”等中文词汇为例,指出烹饪中时间与耐心的要素,与编程中的调试与迭代有着内在相通之处。
Mac mini 通过键盘连接蓝牙鼠标
当Mac mini与蓝牙鼠标意外断连时,通过键盘重新连接是一种高效且独立的解决方案,避免了依赖有线鼠标的不便。核心操作涉及利用系统设置进行蓝牙配对:首先通过Cmd+空格调出Spotlight搜索框,输入“系统设置”并回车进入;随后使用方向键导航至蓝牙选项,并手动使鼠标进入配对模式。关键步骤在于解决键盘焦点无法移动到设置面板右侧的问题,这需要按下Ctrl+F7快捷键开启键盘导航功能,从而允许Tab键正常切换焦点。定位到蓝牙鼠标的“连接”按钮后,按Space键即可完成配对。此外,其他备选方法包括通过Cmd+Option+F
露营装备清单整理
本文整理了一份全面的露营装备清单,旨在帮助露营爱好者,特别是新手,提前做好充分准备。清单涵盖六大核心系统:**基础装备**包括帐篷、天幕、折叠桌椅、营地车及防潮垫等,为露营提供基本生活与休息空间;**餐厨装备**详列了炉具、锅具、餐具、水具及保温箱等,保障户外饮食需求;**辅助工具**涵盖充电宝、防晒防虫用品、头灯及急救包,确保安全与便利;**休闲装备**如蓝牙音箱、户外影院等,丰富营地活动;**消耗材料**则包括饮用水、清洁用品及各类燃料;针对烧烤爱好,另设**烧烤装备**专题。 对于计划过夜露营者,清单额外强调了睡袋、枕头、照明设备、洗漱用品及简单药品的必要性。文章同时提供了十项重要**注意事项**,包括结伴而行、选择正规营地、保持通讯畅通、携带充足饮用水、谨慎生火、制定计划以及环保意识等,这些原则对于保障露营安全与体验至关重要。清单最后还提及了针对特定场景(如汛期或山区露营)的装备建议,体现了其实用性与针对性。
C++ 中的 main 定义
这篇讲的是 C++ 最新标准里一个看似微小却影响行为的细节调整:关于 `main` 函数的定义。 作者直接指出了核心变化——根据最新的 C++ 标准草案,程序入口函数 `main` 不再允许被 `extern "C"` 这样的 linkage-specification 修饰。文章引用了标准原文,明确了这一点。对于很多习惯了在某些项目或编译器下这样写来避免名字修饰的开发者来说,这可能会造成困惑或编译错误。 文章进一步解释了背景:在旧标准和实际编译器实现中,`main` 作为程序入口点,其链接约定有着特殊的隐含处理。允许用 `extern "C"` 修饰是一种非正式的宽容行为,但新标准明确了这一行为是不符合规定的。文章通过展示错误用法与正确用法的代码对比,清晰地指明了正确做法——只需遵循基本的 `main` 函数签名即可。 这提醒我们,依赖编译器的“非标准特性”或历史宽容行为存在风险。随着标准演进,这些模糊地带正在被澄清。对于需要严格符合标准的代码,尤其是跨平台项目,留意此类细节更新很有必要。
竞业协议的相关文章收集
这篇关于国内竞业协议现象的深度合集,汇集了多篇重要文章的核心观点与案例。文章直指国内互联网行业竞业协议被普遍滥用的现状——本应仅针对高管、核心技术及保密人员的限制,已下沉至应届生甚至实习生,成为企业“拿捏”员工的工具。作者梳理了相关法律要点,例如竞业期限最长两年、补偿金一般不低于离职前12个月平均工资的30%,并强调连续三个月不支付补偿则协议自动失效。 合集进一步引入硅谷视角作为对比:加州早在1872年便立法禁止竞业协定,学者认为这促进了人才流动与创新,是硅谷保持活力的源头之一。而美国联邦贸易委员会(FTC)更在2023年提议全国禁止,指出竞业协定会压缩薪资、阻碍创业。通过汇集国内“全网通缉”式的极端案例与硅谷的开放模式,文章呈现了两种截然不同的人才观与创新生态。它既为从业者提供了应对竞业限制的实用法律知识,也引发了对于人才价值与企业权力边界的思考。
一个 VLA (可变长度数组)的实现
这篇讲的是作者如何用C语言实现一个更实用、更安全的可变长度数组库。C99引入的VLA特性因安全问题已被MSVC和Linux内核相继放弃,但在日常开发中,变长数组的需求依然存在。现有的通用方案,如C++的std::vector或简单的void*实现,在类型安全、性能(堆内存分配)和与特定运行时(如Lua)的集成方面各有不足。 作者的方案核心是将VLA拆分为抽象的“句柄”和类型化的“访问器”。通过`vla_using`宏,在栈上创建一个指向实际数据的原生指针作为访问器,同时关联句柄,从而在保证类型安全和原生数组访问性能的同时,提供了清晰的API。为兼顾临时使用与持久引用的不同场景,方案统一了栈上缓存与堆分配的切换逻辑。 更巧妙的一点是,作者针对与Lua交互的场景,实现了利用Lua GC管理内存的第三种模式:小块内存直接分配在C栈上,大块内存则转为Lua临时userdata,随函数退出自动回收,省去了手动清理的麻烦。整个实现展示了如何在C语言的限制下,通过宏技巧和分层设计,构建出一个既高效又贴合实际工程需求的通用数据结构。
iTerm2 (Mac Terminal) 清空当前屏幕内容
这篇讲的是 Mac 终端用户常遇到的一个“洁癖”小问题:执行 `clear` 命令后,屏幕看似干净,但向上滚动依然能看到历史输出,而且在搜索时,之前的内容其实也还在。 文章直接点明了 `clear` 命令的这两个局限性,并给出了一个更彻底的解决方案——使用 iTerm2 自带的快捷键 `Command + K`。这个操作能真正清空屏幕缓冲区,让历史记录在滚动和搜索时都彻底消失。 如果你经常在终端里工作,希望获得一个完全空白、不受旧内容干扰的工作界面,这个小技巧能立刻提升你的使用体验。
技术同学在业务中的成长
这篇文章探讨了技术同学在职业成长中的一个经典困惑:在大团队有机会“造轮子”但晋升竞争激烈,在小团队专注业务却可能成长更快。作者从“什么是业务”出发,清晰地梳理了团队为避免重复建设而进行抽象、分层的必然性,指出“造轮子”本质也是业务的一部分,只是需要更广阔的抽象和服务更大的体量。 文章的核心在于为“业务同学”正名。作者指出,做业务的同学身处一线,直面客户和市场的核心问题,这恰恰是他们的独特优势。但现实矛盾在于,技术价值的评估往往难以直接对应产品结果。因此,作者提出了一个关键的角色进化方向——“产品工程师”。 作者认为,业务同学不应只羡慕“轮子制造者”,而应聚焦于将各种轮子组装成更好的“产品”这辆车。他们面临的业务场景虽不确定,但可以主动去探索和定义业务模型,为其添砖加瓦。这本身就是一个充满挑战和成长空间的新课题。 最后,文章也点破了“大团队技术就一定强”的错觉,强调了环境与个人选择的关系。它鼓励技术人员无论身处何种环境,都能看清自己的价值,做好分内之事,从而实现扎实的成长。
