您现在的位置:首页
--> 算法
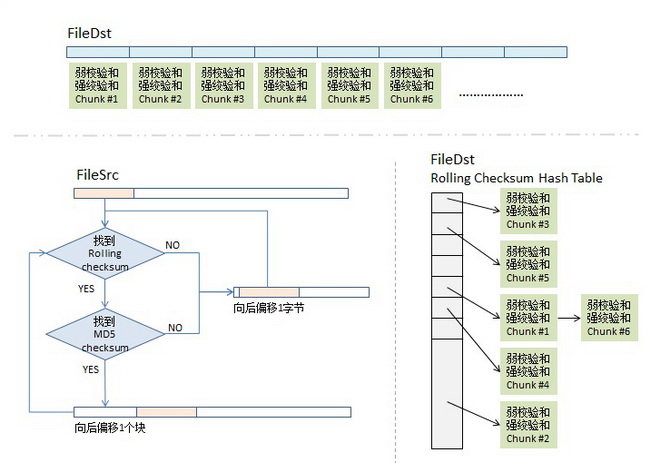

rsync是unix/linux下同步文件的一个高效算法,它能同步更新两处计算机的文件与目录,并适当利用查找文件中的不同块以减少数据传输。rsync中一项与其他大部分类似程序或协定中所未见的重要特性是镜像是只对有变更的部分进行传送。rsync可拷贝/显示目录属性,以及拷贝文件,并可选择性的压缩以及递归拷贝。rsync利用由澳洲电脑程式师Andrew Tridgell发明的算法。这里不介绍其使用方法,只介绍其核心算法。我们可以看到,Unix下的东西,一个命令,一个工具都有很多很精妙的东西,怎么学也学不完,这就是Unix的文化啊。 本来不想写这篇文章的,因为原先发现有很多中文blog都说了这个算法,但是看了一下,发现这些中文blog要么翻译国外文章翻译地非常料,要么就是介绍这个算法介绍得很乱让人看不懂,所以反而让我觉得我应该写下这篇文章,因为别人没搞好。




Linux异步I/O是Linux内核中提供的一个相当新的增强。它是2.6版本内核的一个标准特性,异步非阻塞I/O背后的基本思想是允许进程发起很多I/O操作,而不用阻塞或等待任何操作完成。稍后或在接收到I/O操作完成的通知时,进程就可以检索I/O操作的结果。
在开发C++程序时,一般在吞吐量、并发、实时性上有较高的要求。设计C++程序时,总结起来可以从如下几点提高效率: 并发、异步、缓存。下面将我平常工作中遇到一些问题例举一二,其设计思想无非以上三点。




阅读OTP源码可以帮助你写出更好、更健壮的erlang程序.下面一系列文章就gen_server、gen_fsm、supervisor的源码进行分析, 从erlang级别解释其工作原理, 所有的完整流程图在这里, 第一次写erlang方面博文有错误请帮忙指出. 为什么从gen_server它开始, 因为gen_fsm和它很类似, 而supervsisor本身是一个gen_server. init 图示为一个叫Mod的模块, 它是一个gen_server程序, 绿色方格为调用进程(客户进程), 黄色方格为spawn出的gen进程(服务进程). 不同的泳道表示函数所隶属的模块, 通过这个图可以清晰的看出各个模块至之间的相互调用, 图是使用gliffy所画。
全文译自墙外文章“NoSQL Data Modeling Techniques”,译得不好,还请见谅。这篇文章看完之后,你可能会对NoSQL的数据结构会有些感觉。我的感觉是,关系型数据库想把一致性,完整性,索引,CRUD都干好,NoSQL只干某一种事,但是牺牲了很多别的东西。总体来说,我觉得NoSQL更适合做Cache。下面是正文—— NoSQL 数据库经常被用作很多非功能性的地方,如,扩展性,性能和一致性的地方。这些NoSQL的特性在理论和实践中都正在被大众广泛地研究着,研究的热点正是那些和性能分布式相关的非功能性的东西,我们都知道 CAP 理论被很好地应用于了 NoSQL 系统中(陈皓注:CAP即,一致性(Consistency), 可用性(Availability), 分区容忍性(Partition tolerance),在分布式系统中,这三个要素最多只能同时实现两个,而NoSQL一





solr从1.4版本开始,提供了一种字段类型TrieField(TrieLongField、TrieIntField等),用于范围查询,性能比普通的数值类型要快10倍。为什么会快那么多呢?网上找不到相关资料,通过分析源代码,大概了解了其原理,给大家分享下。 TrieField字段配置 其中precisionStep代表字段值分段保存的时候,截断精度的大小。一般来说,其值越小,索引大小越大,查找速度越快。
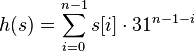



众所周知, CPU是计算机的大脑, 它负责执行程序的指令; 内存负责存数据, 包括程序自身数据. 同样大家都知道, 内存比CPU慢很多. 其实在30年前, CPU的频率和内存总线的频率在同一个级别, 访问内存只比访问CPU寄存器慢一点儿. 由于内存的发展都到技术及成本的限制, 现在获取内存中的一条数据大概需要200多个CPU周期(CPU cycles), 而CPU寄存器一般情况下1个CPU周期就够了. CPU缓存 网页浏览器为了加快速度,会在本机存缓存以前浏览过的数据; 传统数据库或NoSQL数据库为了加速查询, 常在内存设置一个缓存, 减少对磁盘(慢)的IO. 同样内存与CPU的速度相差太远, 于是CPU设计者们就给CPU加上了缓存(CPU Cache).
典型的CPU微架构有3级缓存, 每个核都有自己私有的L1, L2缓存. 那么多线程编程时, 另外一个核的线程想要访问当前核内L1, L2 缓存行的数据, 该怎么办呢? 有人说可以通过第2个核直接访问第1个核的缓存行. 这是可行的, 但这种方法不够快. 跨核访问需要通过Memory Controller(见上一篇的示意图), 典型的情况是第2个核经常访问第1个核的这条数据, 那么每次都有跨核的消耗.


本文介绍了一种基于多版本并发控制(MVCC)思想的Conditional Update解决分布式系统并发控制问题的方法。和基于悲观锁的方法相比,该方法避免了大粒度和长时间的锁定,能更好地适应对读的响应速度和并发性要求高的场景。




consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛; 1 基本场景 比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ; hash(object)%N 一切都运行正常,再考虑如下的两种情况;




测试方法: 对一个含16个Integer/String/Date类型字段的扁平对象作序列化/反序列化,单机多线程循环执行,用循环一定次数之后sleep(1)控制频率,每隔1秒统计一次执行次数,并观察CPU/LOAD/内存等指标(因内存恒定开销,忽略掉)。


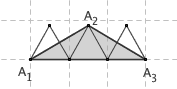
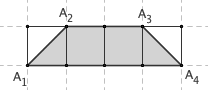
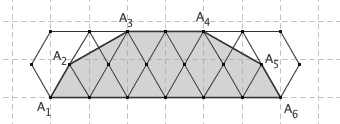
想像一个圆盘在地面上滚动一周,那么圆周上一点所形成的轨迹就叫做旋轮线(或者摆线)。旋轮线下方的面积是多少,这是一个非常有趣的问题。据说, Galileo 曾经用一种非常流氓的方法,推测出了旋轮线下方的面积。他在金属板上切出一块圆片,再在金属板边缘剪下这个圆形所对应的旋轮线,把它们拿到秤上一称,发现后者的重量正好是前者的三倍。于是,他推测,半径为 r 的滚轮所产生的旋轮线,其下方的面积就是 3πr2 。
前段时间谈到了 ringbuffer 在网络通讯中的应用 。有不少朋友写 email 和我探讨其实现细节。 清明节放假,在家闲着无聊,就实现了一个试试。虽然写起来还是挺繁杂的,好在复杂度还在我的可控范围内,基本上也算是完成了。 设想这样一个需求:程序 bind 并listen 一个端口,然后需要处理连接到这个端口上的所有 TCP 连接。当每个连接上要数据过来时,收取这些数据,识别出封包,发送给对应的逻辑层处理。如果数据不完整,则暂时挂起这些数据,直到数据收取完整再行处理。我写的这个小模块实现了这样一组特性,因为使用了唯一的 ringbuffer 缓存所有的连接,可以保证在程序运行过程中,完全没有额外的内存分配操作。
最近几天翻阅了apache的MPM(Multi-Processing Module)机制相关的代码,虽然还有很多细节没有搞明白,但对apache的服务器模型有了一个大体的概念,对于不同的操作系统,apache提供了不同的默认MPM模型,下表是不同操作系统默认的MPM模型: BeOSbeos Netwarempm_netware OS/2mpmt_os2 Unixprefork Windowsmpm_winnt Unix平台则对应着prefork模型,prefork从名字上看意思是预先生成子进程,所以这种模型大致上是怎么工作的我们心里差不多有些认识了,prefork是一种很重要的服务器程序设计模型,对应的还有prethread,prefork一般应用在Unix平台上,因为在服务器启动时需要预告fork出一些空闲的子进程,由它们共同监听客户端的请求,这样来实现快速高并
Memcached是一种应用较广泛的分布式内存对象缓存系统,应用之余总想了解它的实现机理,这也就是开源的好处,以至于每接触一款优秀的开源软件都有去阅读它源代码的冲动,Memcached-1.4.7的代码量还是可以接受的,只有10K行左右,我比较关心的两个方面还是它的进程(线程)管理机制和内存管理机制,这里先简单写一下我对Memcached进程管理方面的理解。 Memcached使用libevent实现事件循环,libevent在Linux环境下默认采用epoll作为IO多路复用方法,这个不重要,接下来要讨论的是Memcached的进程管理模型。
近3天十大热文
-
 [11] 逃出你的肖申克(五):看不见的牢笼(上)
[11] 逃出你的肖申克(五):看不见的牢笼(上) -
[9] [Perl]Moose::Manual::T
-
[9] 关于身份证号的那些事
-
[9] 位置服务类产品的用户状态和地点管理设想
-
[8] 概率语言模型及其变形系列-PLSA及EM算法
-
[8] Eclipse开发Android应用程序入门
-
[8] MySQL error log 输出到sys
-
[8] 怎样获取PHP变量的变量名之PHP实现
-
[8] linux 简单架设防火墙路由器
-
[8] 社交网络语法:关于“Checkin”
赞助商广告
