您现在的位置:首页
--> MySQL
CASE: mysql的IO处理上有抖动, 从日值上观查binlog最大的有(512M)大于max_binlog_size(128M) 原因: 当mysql在处理大事务时,不会进行binlog切换,所有的日值还是会写到一个数据文件里. 如: bulk insert之类的操作 解决办法: 拆分大事务. 或是把大事务处理放到业务低峰期,避免大事务对业务的冲击. 特别提示: 看到这种现象可以通过分析binlog查到是什么操作, 可以通过业务的方面考虑一下怎么规避.



最近在项目中使用了开源OLAP引擎——Mondrian实现一个多维分析系统,在项目后期系统优化阶段使用了Mondrian中的聚合表机制。这里结合 Mondrian官方资料和个人使用经验,对Mondrian中聚合表的概念、应用场景、如何使用、注意事项等内容做一个总结。 1. OLAP相关概念 Mondrian是一个基于Java语言的开源OLAP引擎,它通过MDX语句执行查询,从关系型数据库RDBMS中读取数据,以多维度的形式展示查询结果。 Mondrian通过Schema来定义一个多维数据库,它是一个逻辑概念上的模型,其中包含Cube(立方体)、Dimension(维度)、Hierarchy(层次)、Level(级别)、Measure(度量),这些被映射到数据库物理模型。Mondrian中Schema是以XML文件的形式定义的。
1.InnoDB存储引擎 AIO insert into nkeys values (71,71,71,71,71); Innodb的异步I/O,默认情况下使用linux原生aio,libaio。关于异步I/O的优势,可参考网文[18][19];libaio的限制,可见网文[17]。下面详细分析Innodb 异步I/O的处理步骤。
2012年5月10日,Sauce Labs公司的首席架构师Steven Hazel,写了一篇关于弃用NoSQL数据库CouchDB产品,介绍他们将Couch数据库的数据迁移到MySQL数据库平台中。 在Sauce Lab(酱油实验室)里,我们刚刚庆祝完成一个重大项目—将最后的CouchDB数据库转变为MySQL数据库,以提高服务正常运行时间和可靠性。 由于大部分无故停机的是由于CouchDB数据库宕机引起的,因此完成这种迁移是我们一个重要的里程碑。
1. like %keyword 索引失效,使用全表扫描。但可以通过翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全表扫描。 2. like keyword% 索引有效。 3. like %keyword% 索引失效,也无法使用反向索引。
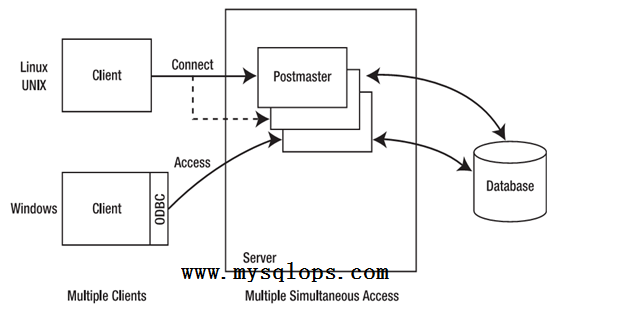
PostgreSQL介绍 本书都是关于一个最近最成功的开源产品,一个名叫PostgreSQL的关系数据库。
这周阿里集团DBA内部分享时,支付宝的黄忠同学提了一个问题,关于InnoDB索引page 的利用率。 page利用率 主要是指btee里面每个page的使用被使用的空间大小。我们知道InnoDB默认一个page大小是16k。但实际使用情况不会总用满.


MySQL数据库产品提供了三种特殊用处的数据类型: SET(集合类型)、ENUM(枚举类型)、BOOL/BOOLEAN(布尔类型),而多数开发工程师,甚至DBA从业者对如何使用好这三种数据类型,以及在什么样的应用场景下使用并不十分清晰,这三种数据类型与微整型TINYINT数据类型关系比较亲近,实际项目中大家也多采用TINYINT代替前三者的功能,为此详细分析这四种数据类型,让我们大家一起详细分析清楚。



当你需要通过optimze table优化表空间,若是使用percona版本则最好先打开expand_fast_index_creation;若是官方版本,则建议自己写脚本建临时表,按照上述的过程a~e来执行,达到最优的效果。




有同学上周问了个问题 “MySQL 里面的order by rand()”是怎么实现的。我们今天来简单说说MySQL里的order by。 几种order by的情况 乍一看这个问题好像有点复杂,我们从最简单的case开始看起。
对比发现中间件中共同实现的功能有:路由规则、故障转移、集群复制、读写分离。其中路由规则实现有路由表、hash、B-tree方法,路由表实现比较简单、只能进行唯一搜索,但是也要考虑单点、负载问题,游戏行业可以使用该方法,在扩展节点的时候不必进行数据迁移。Hash方法实现缺点是在增加数据节点的时候需要迁移部分数据、只能进行唯一搜索,优势是不会有单点问题,因为是通过hash算法映射的,在效率上也比路由表高。B-tree效率不高,但能实现范围查找。故障转移需要做心跳检测与主从自动切换。读写分离大部分公司有条件的公司自己会独立开发读写分离的中间件,没有条件的公司可以自己用程序简单实现,也可以使用amoeba和MySQLProxy,前者在淘宝平台生产线上,后者都建议不要使用,效率不理想,而且目前还是alpha版本。技术大会结束之后,我相信很多公司也开始倒腾中间件了,技术人也开始在公司推进这项技术,希望各大公司能够真正将这些中间件开源出来,分享给我们IT人员
InnoDB 是一个非常不错的 MySQL 的存储引擎,目前使用非常广泛基本所有的网站和项目,我想都会优先选择这个,这个也有很好的诊断和微调的工具.我发现其中一个缺点,就是磁盘空间管理时设计...




来自网易研究院的MySQL内核技术研究人何登成,把MySQL数据库InnoDB存储引擎的多版本控制(简称:MVCC)实现原理,做了深入的研究与详细的文字图表分析,方便大家理解InnoDB存储引擎实现的多版本控制技术(简称:MVCC)。

2012年4月13日至4月15日为期3天时间,在北京 福朋.喜来登酒店举办第三届数据库技术大会(简称:DTCC),到会技术人员数超过1000人,48位演讲嘉宾,超过200位数据库领域专家到场,一共举办了12个技术专场主题分享,7个圆桌讨论活动,现已顺利圆满地结束,回顾个人参加三界数据库技术大会的经历和心得,为主办方澳新传媒举办下届数据库技术大会(简称:DTCC),给出一点个人建议,也对期待参加的技术和管理人员给出点个人建议。 数据库技术大会(简称:DTCC)和架构师大会的举办,给技术领域提供了一个非常好的技术交流平台,能帮助更多技术人员交换各自的心得体会,也能促成更多技术人员互相认识和结为朋友,同时能促进大家的技术与管理水平的提高,尤其是大家会议期间的私下交流。当然,也有很多互联网公司借数据库技术大会和系统架构师大会的机会,招揽技术人才。



在实现levelDB挂载成MySQL引擎时,发现在实际存储是key-value格式时候,MySQL的异构数据同步,可以更简单和更通用。 以tair为例,简要描述一下以MySQL为基础的一种方案。 所谓异构数据同步,是指应用只更新MySQL,而由后端的某些机制将这些更新应用到其他数据存储服务上。


理论上来说,如果MySQL数据库InnoDB存储引擎的buffer足够大,就不需要将数据本身持久化。将全部的redo log重新执行一遍就可以恢复所有的数据。但是随着时间的积累,Redo Log会变的很大很大。如果每次都从第一条记录开始恢复,恢复的过程就会很慢,从而无法被容忍。为了减少恢复的时间,就引入了Checkpoint机制。
虽说Redo Log将数据的操作细分到了页面级别。但是有些在多个页面上的操作是逻辑上不可分裂的。比如B-Tree的分裂操作,对父节点和2个子节点的修改。当进行恢复时,要么全部恢复,要么全部不 恢复,不能只恢复其中的部分页面。InnoDB中通过mini-transaction(MTR)来保证这些不可再分的操作的原子性。
近3天十大热文
-
 [337] WEB系统需要关注的一些点
[337] WEB系统需要关注的一些点 -
[15] 哪本书是对程序员最有影响、每个程序员都该阅读
-
[13] 一次神奇的MySQL优化
-
[13] 业务流程图的绘制流程分享(一)
-
[13] 修改系统最大文件句柄数
-
[13] InnoDB insert性能拐点测试
-
[12] 我的git笔记
-
[12] Python程序的执行原理
-
[11] Android设计中的.9.png
-
[11] 深入剖析 redis replication
赞助商广告
