您现在的位置:首页
--> 网络系统

Tcp-proxy是什么东西就不说了,搜索本站就能找到答案,说说最近碰到的几个问题。 1)keep-alive 如果server或client开启keep-alive,需要tcp-proxy也能感知。但是keep-alive本身是不携带有效的数据(通常是最后收到并且已经确认的一个字节),所以直接转发会有问题(tcp-proxy转发会重写tcp header,而且tcp-proxy之上的应用不能处理这个包)。所以说keep-alive是tcp层的行为,而不是应用层的行为,只要tcp-proxy的两端处理就可以了。由于tcp-proxy接管的tcp连接,所以最好是两边都能够发出keep-alive packet,这样才能完成协议所规定的功能。
【nslookup何许人?】 nslookup命令,是Linux里非常常用的网络命令,简而言之就是“查DNS信息用的”。 通过man nslookup可以看到对于nslookup的官方解释是“query Internet name servers interactively”。 【nslookup作者何许人?】 通过man nslookup可以看到其作者是Andrew Cherenson,我寻找到了他的Linkedin主页,原来 他是一位计算机科学的高材生,曾经就读于哈佛大学和加州大学伯克利分校。 目前就职于ChoiceStream公司, 【系统没有nslookup命令?】 如果你的Linux系统没有nslookup命令,那么八成是你没有安装bind-utils包。
我相信使用nslookup的同学一定比使用dig的同学多,所以还是有必要花些时间给大家介绍一下dig的。 dig,和nslookup作用有些类似,都是DNS查询工具。 dig,其实是一个缩写,即Domain Information Groper。 一些专业的DNS管理员在追查DNS问题时,都乐于使用dig命令,是看中了dig设置灵活、输出清晰、功能强大的特点。
我之前一直是使用ssh –D的方式翻墙,但是这么做有个缺点,需要在用户的机器上安装一个软件,并且ssh会经常断(即使加了keep alive)。后来我一直在想,为什么不直接走http或者socks协议呢?我觉得主要原因是:通信没有加密。 Chrome开了一个名为Secure Web Proxy的项目,旨在让浏览器支持HTTPS协议的proxy server。目前不光chrome,firefox也支持了。此外,Chrome还引入了一个名为SPDY的协议,通过对HTTPS做略微的修改,使得在单个SSL连接上可以同时传输多个HTTP请求。因为减少了HTTPS握手次数,可以大大提高proxy的相应次数。 综上所述,用SPDY协议来翻墙,比ssh -D好多了! 最近我从网上找了一段代码,发现可以很快速的利用node.js搭建一个SPDY协议的proxy server,下面分享给大家。
面试一小伙,老生长叹的问题,介绍一下TCP flags,小伙说多了,SYN, FIN在ACK的时候需要占一个Byte的数据,而其他几个不需要。于是反问之,为什么不要?小伙支吾一阵说,可能是其他几个不重要吧。这个问题其实很简单,对于需要ACK确认收到的标记,需要占用一个Sequence值。例如,你发送一个仅有FIN没有数据的报文,TCP一定要确认收到一把,而这种确认只能通过sequence加加。这个同标记的重要与否无关。其他的Flag是单向的不需要确认,尤其对于ACK,协议设计上就不允许确认,因为如果ACK需要确认,则协议必然陷入死循环不可自拔。对于SYN, FIN由于需要确认,因此逻辑上是Data的一部分。其实TCP的多数option也是需要确认的,逻辑上也是data的一部分。但Option设计本身就有option级别的确认机制,不需要利用sequence在搞一把。



最近在项目中碰到了比较多 HTTP 相关的问题,小组对这些问题进行了学习和总结。 ch01. 跨域Ajax 背景小故事: 开放平台通过 JS 的方式将淘宝的核心功能集成到第三方网站,以扩大交易生态圈。 目前已发布登录、购物车等组件。 作为底层支持的 JS SDK 需要提供小巧的跨域XHR功能. ch02. 反向Ajax 背景小故事: 有Ajax,自然还有反向 Ajax 。本着折腾的精神,对这部分知识点也做了一些了解。 ch03. HttpOnly cookie 和 第三方 cookie 背景小故事: 在页面中嵌入一个跨域的iframe,在某些浏览器中,iframe的js无法操作cookie。 此外,第三方,可能无法正确发送 cookie。 等等奇怪的问题,都跟小小的cookie有关。

NAT是在传输层及以上做的,传输层最主要的2个协议是TCP和UDP。对于TCP和UDP而言,每个包都有很基本的4个要素:src ip、src port、dst ip、dst port。 根据在做NAT的时候是否保留src ip和src port,可以把NAT分为这么三种: Cone: 将src ip映射到一个固定的IP,并且将src port映射到一个固定的Port,无论dst ip和dst port是什么。 Single IP address, symmetric:将src ip映射到一个固定的IP,将src port映射到一个随机的port,但是保证对于相同的(dst ip,dst port), src port始终相同。(否则双方没法通话啊,回来的包回给哪个端口呢?) Multiple IP address, symmetric:与上面类似,但是src ip可能会有多个。
我们在做网络服务器的时候,通常会很关心网络的带宽和延迟。因为我们的很多协议都是request-reponse协议,延迟决定了最大的QPS,而带宽决定了最大的负荷。 通常我们知道自己的网卡是什么型号,交换机什么型号,主机之间的物理距离是多少,理论上是知道是知道带宽和延迟是多少的。但是现实的情况是,真正的带宽和延迟情况会有很多变数的,比如说网卡驱动,交换机跳数,丢包率,协议栈配置,光实际速度都很大的影响了数值的估算。 所以我们需要找到工具来实际测量下。 网络测量的工具有很多,netperf什么的都很不错。 我这里推荐了qperf,这是RHEL 6发行版里面自带的,所以使用起来很方便,只要简单的: yum install qperf 就好。
网站受到DDOS的攻击,Inbound最高请求58.85Mb/sec 。尽管一开始解决问题的思路是错误的,但是在这个过程中,我们思考问题的思路对团队的成长有所帮助,我们知道什么方法无法解决问题。



一、工具介绍 Tcpcopy是一个分布式在线压力测试工具,可以将线上流量拷贝到测试机器,实时的模拟线上环境,达到在程序不上线的情况下实时承担线上流量的效果,尽早发现bug,增加上线信心。 Tcpcopy是由网易技术部于2011年9月开源的一个项目,现在已经更新到0.4版本。与传统的压力测试工具(如:abench)相比,tcpcopy的最大优势在于其实时及真实性,除了少量的丢包,完全拷贝线上流量到测试机器,真实的模拟线上流量的变化规律。二、Tcpcopy的原理 1.流程现在以nginx作为前端说明tcpcopy的原理: 上图中左边是线上前端机,右边是测试前端机。线上前端机开启tcpcopy客户端(tcpcopy进程),测试前端机开启tcpcopy服务端(interception进程),且两台机器上都启动了nginx服务。
xxx.xxx.0.0/24代表 是A类地址 主机为8位表示xxx.xxx.0固定,后面是可变 xxx.xxx.0.0/16 代表B类地址 主机为16为表示xxx.xxx固定,后面是可变 简单的...


MINA网络通信框架 基本介绍: Apache MINA 2是一个开发高性能和高可伸缩性网络应用程序的网络应用框架。它提供了一个抽象的事件驱动的异步API,可以使用TCP/IP、UDP/IP、串口和虚拟机内部的管道等传输方式。Apache MINA 2可以作为开发网络应用程序的一个良好基础。 Mina 的API 将真正的网络通信与我们的应用程序隔离开来,你只需要关心你要发送、 接收的数据以及你的业务逻辑即可。 mina的基本架构: 在图中的模块链中,IoService 便是应用程序的入口,相当于我们前面代码中的 IoAccepter,IoAccepter 便是 IoService 的一个扩展接口。IoService 接口可以用来添加多个 IoFilter,这些 IoFilter 符合责任链模式并由 IoProcessor 线程负责调用。
网络防火墙会切断长时间空闲的TCP连接,这个空闲时间具体多长可以在防火墙内部进行设置。防火墙切断连接之后,会有下面的可能: 切断连接之前,连接对应的Oracle会话正在执行一个耗时特别长的SQL,比如存储过程而在此过程中没有任何数据输出到客户端,这样当SQL执行完成之后,向客户端返回结果时,如果TCP连接已经被防火墙中断,这时候显然会出现错误,连接中断,那么会话也就会中断。但是客户端还不知道,会一直处于等待服务器返回结果的状态。 切断连接之前,Oracle会话一直处于空闲状态,在防火墙中断之后,客户端向Oracle服务器提交SQL时,由于TCP连接已经中断,这时客户端侦测到连接中断,那么客户端就会报ORA-3113/ORA-3114这类错误,然后会话中断。但是在Oracle服务器端,会话一直在处于等待客户端消息的状态。
• 时延和带宽的关系

• 5代防火墙
Cissp AIO说防火墙已经发展了5代,估计很多防火墙专业人士都不太明白是怎么回事。对专业人士来说,拿cissp证,首先要保证自己掌握的术语能和业界保持一致,否则就会范概念性错误 1st generation: packet filtering,包过滤防火墙 2st generation: application-level proxy,应用代理,这里特指用户空间的代理 3st generation: circuit-level proxy,电路级代理,这里特指socks代理,这个代理和上面那个代理的区别是 这个代理是和应用无关的,不需要了解应用细节,任何应用都可以用。早期有很多socks代理,比如sygate之类 的,现在很少看见了 4st generation: stateful,状
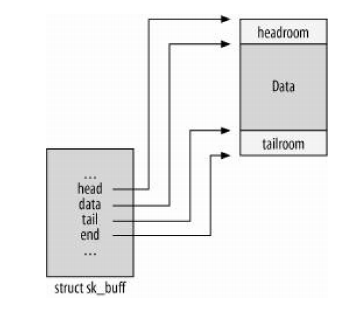
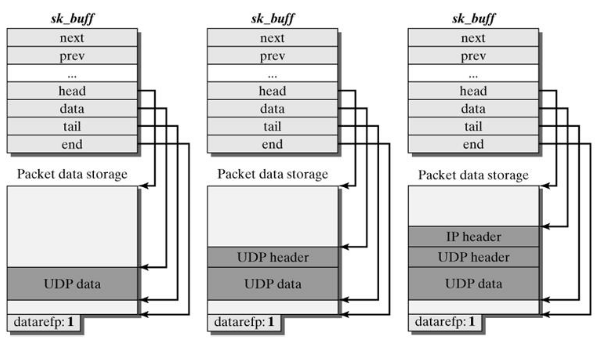
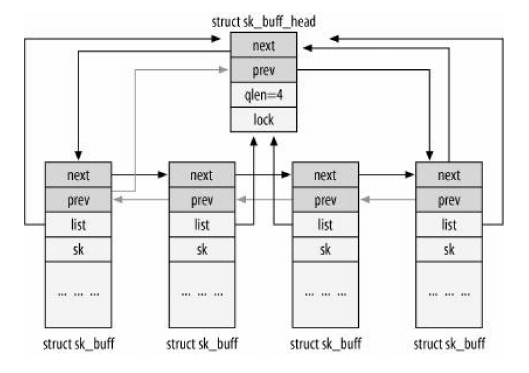
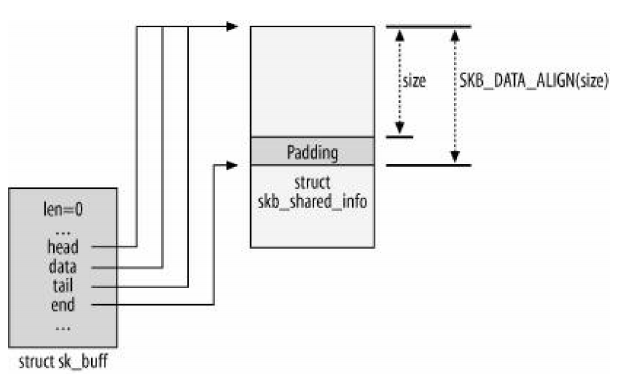
译者注: 原文写于2003年,文中描述的不少内容已经发生了改变,在不影响愿意的情况下,我擅自增删了一些内容. 翻译过程中找到的好资料: How SKBs Work Evaluation of TCP retransmission delays Congestion Control in Linux TCP Anatomy of the Linux networking stack — From sockets to device drivers Guide to IP Layer Network Administration with Linux Linux内核源码剖析 —TCP/IP实现 Understand Linu
近3天十大热文
-
 [16] Go Reflect 性能
[16] Go Reflect 性能 -
[14] iOS可视化编程 Tips 之“无需代码设置
-
[13] iTerm2 (Mac Terminal)
-
[13] 浅谈Web安全验证码
-
[12] 手把手教你CSRF防护
-
[12] 浏览器的工作原理:新式网络浏览器幕后揭秘
-
[12] 基于HTTP缓存轻松实现客户端应用的离线支持
-
[11] Android设计中的.9.png
-
[11] osx平台上lol英雄联盟launcher启
-
[11] 自建DNS以防止GFW干扰
赞助商广告
