逻辑回归算法学习与思考
这篇讲的是逻辑回归算法的原理与实现。作者从算法的“分类边界拟合”核心思想切入,细致拆解了预测函数h(sigmoid)与损失函数J(θ)的设计逻辑。文章不仅推导了梯度下降优化θ的数学过程,还将其向量化,并对照《机器学习实战》中的Python代码进行解读,让公式与实现一一对应。在实际应用部分,作者以sklearn库为例展示了模型调用流程,并特别结合网络安全场景进行了预测分析。整体上,文章完成了一条从数学推导到代码实现,再到领域应用的学习路径,适合想扎实掌握逻辑回归的读者。
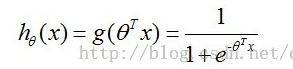
有追求优秀之心的程序员
这篇文章从一条引发热议的微博出发,探讨了当下程序员群体中基础能力参差不齐的现象。作者指出,行业门槛降低使得许多仅能“完成任务”的个体进入,但这并不应成为放弃专业追求的理由。 文章的核心观点是,区分“普通”与“优秀”程序员的关键,在于是否具备“追求优秀之心”。作者以面试者连冒泡排序都不会写为例,强调基础逻辑思维的重要性。优秀的程序员不仅能实现功能,更擅长进行业务抽象,通过合理的技术选型确保系统在苛刻条件下依然准确可靠。 最后,文章鼓励那些理解程序内在、能进行逻辑抽象的程序员,应当认识到自己的稀缺性与价值,相信自己“出身高贵”,理应获得更好的回报。整篇文章在技术讨论中,传递了关于职业尊严与自我期许的思考。
跳跃表
这篇讲的是从Redis底层实现引出的跳跃表数据结构。作者从结构图入手,说明它本质是多层链表的组合,底层S0存储有序数据,上层作为索引加速查找。查找时从顶层向下逐层扫描,插入时则通过随机概率P决定新节点能“跳”到多高,从而在期望O(logn)时间内完成操作。 文章展示了一组实验数据,对比了不同P值(如1/2、1/e)对平均操作时间、列高和跳跃次数的影响,直观体现了参数选择的权衡。最后,作者引用了Redis作者antirez的观点,点出跳跃表相比平衡树的核心优势:内存占用可控、对范围查询(ZRANGE)友好、实现与调试更简单。文末也补充说明,这种简单高效的特性使其同样适合算法竞赛场景。
从Java和JavaScript来学习Haskell和Groovy(类型系统)
这篇技术文章从Java和JavaScript的类型系统出发,对比分析了Haskell和Groovy在类型设计上的核心差异。作者首先厘清了动态类型与静态类型、强类型与弱类型、类型推导等基础概念,并逐一拆解了四种语言的类型特性:Java是典型的静态强类型加显式指定,JavaScript则以动态弱类型和类型推导为主,Groovy提供了双模式——既能通过def实现动态推断,也能用显式类型转向静态检查,而Haskell则以静态强类型和类型推导体现了函数式语言的严谨性。 文章进一步深入到数据类型和函数行为的细节对比。例如,JavaScript中instanceof和typeof的混乱结果、Groovy的flow typing如何在运行时根据赋值推断类型,以及Haskell如何通过类型系统保障不变性。这些具体代码示例生动展示了语言设计背后的哲学:动态语言偏向灵活性,静态语言强调安全性。通过这样的跨语言比较,读者能更直观地理解不同类型系统的适用场景,比如Groovy如何在兼容Java的同时融入函数式特性,而Haskell又如何通过纯类型系统避免运行时错误。
大数据过滤及判断算法 -- Bitmap / Bloomfilter
这篇讲的是如何用极低的空间成本,高效判断一个元素是否存在于海量数据集合中。作者从一道常见的面试题出发,引出了两个核心数据结构:Bitmap与Bloomfilter。 文章首先剖析了Bitmap,它本质上就是一块连续的内存位图,每个bit(0/1)直接对应一个元素的“无/有”。作者展示了如何通过简单的位运算(`/8`和`%8`)定位到具体的bit位,并给出了一个完整的C++代码示例,用于在一个10万规模的集合中精确查找缺失的数字。Bitmap的优点是100%准确,但缺点是所需内存与元素值的范围直接相关。 接着,文章重点介绍了Bloomfilter。它通过多个哈希函数对同一个值进行多次哈希,将结果映射到不同的bit位上。这种设计能用远小于Bitmap的内存处理更海量的数据,但代价是存在理论上的误判——可能将不在集合的元素误判为“存在”。作者解释了误判率与哈希函数数量、内存大小的关系,并提供了包含三种经典哈希函数(BKDR、FNV、DEK)的实现代码。 文末,作者还留下了一个思考题:对于“从1到100万无序数中找出被随机取走的N个数”这个问题,除了这两种方法,还可以如何利用数学性质(如求和、求积)来间接求解?这展示了不同场景下算法选择的灵活性。
Trie树(字典树) 最热门的前N个搜索关键词
这篇讲的是Trie树,也叫字典树,一种专门用来高效处理字符串的树形数据结构。它的核心思想很巧妙,通过“空间换时间”,利用字符串的公共前缀来共享存储路径,从而最大化地减少不必要的比较,让查询和插入操作的时间复杂度直接与单词长度挂钩,而不是单词数量。 文章里用了一组清晰的图示和例子,一步步展示了Trie树是如何从零构建起来的。比如,当你有 `inn, int, at, age` 这些单词时,像 `inn` 和 `int` 就可以共享 “in” 这个前缀的分支。这种结构让查找操作变得非常直接:只需顺着字符路径走到底,再检查终点节点是否被标记为“存在”即可。 更实用的是,文章没有停留在原理,而是直接给出了两个经典的应用场景。一个是统计海量文本中出现频率最高的词,另一个是在千万级的搜索日志中,用有限内存找出最热门的查询串。在这两个问题里,Trie树都扮演了高效的计数和索引角色,再结合堆进行排序,就能得出最终结果。对于想理解如何将数据结构用于解决实际工程问题的人来说,这篇文章的路径很清晰。
Scheme 初步
这篇讲的是作者出于函数式编程启蒙、接触经典教材《计算机程序的构造和解释》以及扩展 Emacs 等现实考虑,开启 Scheme 语言学习之旅的初体验。 文章没有高深理论,而是以轻松引导的方式,带读者跨过环境配置这道常见的“入门第一坎”。从在线 REPL 到本地安装,作者分享了让程序“跑起来”的最短路径。核心语法部分从最基础的 `( + 1 1 )` 聊起,清晰拆解了括号、前缀表示法和函数调用这些 Lisp 家族的标志性特征,帮助读者建立最初的语感。 作者坦言中文资料稀缺,因此参考了日文教程并对比了不同译本质量,文章本身也是学习过程的整理备忘。整体而言,这篇记录亲切、务实,为那些对函数式编程好奇又不知从何入手的开发者,提供了一个低门槛的起点和一份真诚的学习地图。
一道随机数题目的求解
这篇探讨了一个经典的随机数构造问题:如何基于均匀的1~5随机数函数,实现均匀的1~7随机数函数。作者从直观的思路入手,展示了通过二维数组映射与拒绝采样的核心方案,并提供了对应的Java实现。 然而,文章的价值不止于算法本身。作者在千万次数据测试中,意外发现生成结果的分布并不均匀,某些数字的出现频率显著偏高。经过深入排查,问题被追溯到随机数种子的精度上——即使使用纳秒级时间戳,快速连续调用时获取的种子值仍可能相同,导致随机序列重复,进而破坏了分布的均匀性。 文章通过对比实验(如将种子改为毫秒级、增加调用间隔)验证了这一猜想,揭示了用“小随机”合成“大随机”时,底层伪随机数生成器的缺陷会被放大。这对于理解拒绝采样的实际应用边界,以及随机性工程实现中的细节陷阱,提供了非常具体的参考。
Cuckoo Filter:设计与实现
这篇讲的是如何设计和实现一种名为 Cuckoo Filter 的高效过滤器。作者从实际业务中海量数据快速查询的需求出发,指出经典的 Bloom Filter 虽然空间利用率高,但存在无法删除元素的硬伤,一旦删除就会导致漏报。 为了解决这个问题,文章引入了布谷鸟哈希(Cuckoo Hashing)的设计思想。每个元素有两个哈希位置,发生冲突时,新元素会“踢走”原有元素,并利用其备用位置重新安置,就像布谷鸟侵占别的鸟巢一样。通过使用包含多个槽位的桶结构,可以大幅缓冲碰撞几率,实现高达 80% 以上的空间占用率(论文数据超过 90%),同时支持可靠的插入、查询和删除操作。 作者随后展示了自己用不到 500 行 C 代码实现的完整案例。核心思路是在内存中维护一个轻量级的哈希表,仅存储元素的部分摘要(tag)来快速过滤,将完整数据存放在后端存储(如 Flash)。这样查询时能最大程度避免不必要的磁盘读取。代码清晰地定义了哈希表、槽位结构,并实现了查询、插入等关键操作,验证了该方案在正确性和效率上的可行性。
用 2d 缩放及斜切变换模拟斜视角下的旋转
这篇讲的是作者从一次游戏体验出发,发现游戏《Invisible Inc》在低配电脑上依然流畅运行等距视角(isometric)下的旋转动画,并由此推敲其图形实现原理的过程。 通过分析游戏资源文件,作者发现场景物件(如门和墙)仅有一到两张正面图片,并非预渲染多角度素材。其核心思路是:游戏引擎以2D方式运行,利用仿射变换模拟了3D的斜视角旋转。具体做法是先对图片进行X轴缩放,再施加一个特定的斜切变换,最终通过一个整合后的矩阵(如文章中推导的[cos(x), sin(x)/2, 0, 1, 0, 0])在实时运算中变形图片,制造出透视错觉。作者还通过一段CSS代码直观演示了这一变换效果。 文章末尾,作者分享了为该游戏制作中文汉化Mod时遇到的两个实际问题及其解决方法,这些关于游戏文本排版引擎和本地化字符串格式化的经验,对同类型工作也有参考价值。整体上,文章从现象剖析到原理推导,再到工程实践,是一次有趣的技术探索。

Pinterest的Feed架构与算法
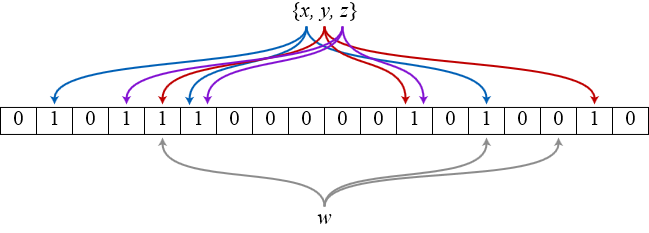
这篇讲的是Pinterest如何将首页Feed流从简单的时序排列,升级为高性能、高可用的个性化推荐系统。随着流量增大,约1/3的访问指向Feed页,工程师面临的核心挑战是:如何在保证99.99%可用性的前提下,为每个用户动态生成个性化的高质量内容。 核心方案是一个分层的“Smart Feed”架构。它不再按时间排序,而是按权重优先展示。系统由三个关键服务构成:Feed Worker负责接收新内容并为每个用户独立计算权重,放入优先级队列;Feed Content Generator根据队列生成新的、按优先级排序的Pin流;Smart Feed Service则负责整合新内容与历史快照,确保即使在新内容生成服务异常时,用户也能快速看到历史列表,实现优雅降级。 存储层的设计尤为巧妙。面对海量数据和高写入QPS,Pinterest采用了双HBase集群方案。主集群处理写入,通过异步任务将数据同步到备用集群。读取时则优先从轻量的“物化存储”集群获取历史列表,再与主集群的新内容合并。这一设计不仅优化了读写延迟,更通过跨可用区的备份,将整体可用性提升至99.99%以上。
缓存算法–LRU
这篇讲的是两种经典的缓存淘汰算法:LRU和它的改进版LRU-K。文章开门见山,先解析了LRU(最近最少使用)的核心思想——它用一个巧妙的链表来实现,新数据插入头部,每次访问都把数据提到最前,满了就淘汰尾部那个“最久没碰”的。这种策略在热点数据集中时效率很高,实现也简单。 但文章也指出了LRU的软肋:一旦出现偶发的批量扫描,会挤掉很多热门数据,造成严重的“缓存污染”。为了解决这个问题,文章引入了LRU-K。这里的“K”代表一个访问次数阈值,比如我们常说的LRU-2。它不再因为一次访问就把数据加入缓存,而是让数据在历史队列中先“排队”,只有被访问了K次,证明它确实是热点,才获准进入缓存队列。 这样一来,LRU-K的命中率通常比LRU更高,能有效抵抗缓存污染。但天下没有免费的午餐,它的实现需要维护额外的访问历史队列并进行排序,算法复杂度、内存消耗和CPU开销都比LRU要高。文章最后也点明了选择的关键:LRU胜在简单高效,适合大多数常规场景;而当你面对严重的访问模式波动时,LRU-K(尤其是LRU-2)提供了一个更稳健的选择。
基于漏桶(Leaky bucket)与令牌桶(Token bucket)算法的流量控制
这篇讲的是高并发系统限流中的两个经典算法——漏桶与令牌桶的核心差异和适用场景。文章以大促流量为背景,引出限流对系统稳定性的必要性。 漏桶算法被形象地比喻为一个底部有孔的桶,它强制数据以固定速率流出,哪怕输入流量是突发的,它也能起到削峰填谷、强行平滑流量的作用。 而令牌桶则不同,它以固定速率向桶中放置令牌,请求需要消耗令牌才能通过。文章特别指出,令牌桶允许桶内积累一定数量的令牌,因此能较好地应对突发流量,在平均限流的同时保留了灵活性。文中也提到了Guava的RateLimiter,其SmoothBursty实现正是令牌桶的优化,能积攒令牌应对短时高峰,而SmoothWarmingUp则实现了漏桶式的预热限流。 作者通过对比明确了二者的本质区别:漏桶强在“恒定速率”,令牌桶强在“允许突发”。选择哪种算法,关键取决于你的业务流量是需要严格平滑,还是需要在平均速率约束下应对可预测的突发。
一致性哈希算法(consistent hashing)
这篇讲的是分布式系统中一个经典问题的优雅解法:一致性哈希算法。作者从最简单的哈希取模(id % N)方式切入,指出其致命短板——一旦集群节点数(N)因扩容或宕机而变化,几乎所有数据的映射关系都会被打破,导致缓存雪崩,后端压力骤增。 为了解决这个“牵一发而动全身”的问题,一致性哈希将哈希空间组织成一个虚拟的环形。节点被映射到环上,数据也映射到环上,并沿顺时针方向找到的第一个节点作为处理者。这样,当增加或删除节点时,只有相邻节点间的数据映射会发生变化,实现了影响范围的局部化。 文章进一步指出,若物理节点较少,可能导致负载在环上分布不均。为此引入了“虚拟节点”概念——为每个物理节点生成多个虚拟分身,均匀分布在环中,从而使负载更加均衡,但会增加一次查找开销。 最后,文章还归纳了评判一致性哈希算法优劣的四个核心标准:平衡性、单调性、分散性和负载。这篇内容清晰地将一个解决分布式数据路由问题的核心算法,从痛点、原理到优化与评估,串联成了一条完整的逻辑链。
我为什么要使用哈希
这篇讲的是如何用哈希技巧解决一个经典的算法问题:在二叉树中找出所有结构完全相同的子树。 文章从一道大厂面试题切入。问题要求给定一棵二叉树,找出所有彼此完全相等的子树对。作者分享了自己的通过面试的解法,核心思路正是借助哈希。通过后序遍历整棵树,为每个节点计算一个哈希值——叶子节点用一个固定值(比如 md5("")),非叶子节点则将其左右子树的哈希值拼接后再次哈希。这样,任何子树都能被映射为一个唯一的哈希指纹。 计算出所有子树的哈希后,将它们放入哈希表。哈希值相同的子树,其结构“有可能”完全相同,但需要二次验证以排除哈希冲突。验证过程是递归地同时遍历两棵树,检查所有节点的左右子树存在状态是否一致。文章还提到了一个关键的优化:通过记录子树深度,在验证前就能排除掉大量哈希值相同但深度不同的“伪匹配”,极大地减少了不必要的递归检查。 整个过程清晰地展示了哈希作为一种“指纹”技术,在加速查找与比对操作中的强大作用,将复杂问题的复杂度显著降低。
Java程序员必知的8大排序算法
这篇讲的是Java程序员几乎绕不开的排序算法集合。排序是编程基础,但很多人可能只记得零散的冒泡和快排,对其他几种知其然不知其所以然。这篇文章就系统性地梳理了直接插入、希尔、简单选择、堆排序等经典算法。 它不像教科书那样堆砌公式,而是像一张清晰的导航图,先用一张图展示8种排序之间的演进与关系,帮助读者建立整体认知。对于每一种算法,都拆解成三部分:先讲清楚核心思想和解决问题的逻辑,比如堆排序如何借助“堆”这种数据结构进行树形选择;然后给出一个直观的排序实例图,让抽象过程可视化;最后附上可直接运行的Java代码,将思想落地。 尤其值得一提的是,文章在讲解复杂算法(如堆排序)时,通过分解“建堆”和“交换”两个关键步骤的可视化过程,让算法的巧妙之处一目了然。这种从原理、图示到实现的递进式讲解,能帮助开发者不仅学会怎么用,更理解算法背后的设计考量,从而在面对不同数据规模或特征时,能更从容地做出选择。
在白板上写代码是有难度的
这篇讲的是技术面试中那个让不少人头疼的环节:白板编程。作者从自己作为微软团队面试官的经验出发,给出了一个核心观点——面试官真正在考察的,并不是你能否当场写出语法完美无误的代码。 他理解白板没有智能感知和语法高亮,因此不介意你出现参数顺序错误这类“小瑕疵”。真正看重的是你的问题解决过程:是急于动手,还是先理清思路?是否主动识别并澄清了需求中的模糊点?会优先攻克难点还是先处理简单的部分? 文章以几个经典面试题(如实现栈、打乱数组)为例,点明了关键:很多问题本身就暗藏陷阱,比如字符串处理需要考虑不同编码,数组随机化要区分安全场景与测试场景。忽略这些“真实世界”的考量,代码设计就无从谈起。 作者鼓励应聘者,在编写代码时就要像开发者一样思考:如何测试?如何处理异常输入?代码是否健壮、可维护?他认为,展现出这种工程思维,远比纠结于一时的语法记忆更能证明你的潜力。最后他也坦言,技术面试本就艰难,聪明如他也曾被拒,这本身就是一个值得准备的过程。
用 JS 复制艺术
这篇讲的是作者如何用 JavaScript 来模仿著名艺术家草间弥生的点画作品《无限网》。作者首先细致观察了原作,发现其特点在于圆点大小不一、带有扭曲且互不重叠,整体呈现出一种有序的流动感。 核心实现思路相当巧妙。作者没有追求像素级的完美复制,而是选择用最基础的循环和数学函数来近似。通过嵌套的循环遍历画布的像素坐标,利用正弦与指数函数的组合来计算每个圆点的位置与半径,并加入了随机偏移来模拟手绘的不规则感。仅仅几十行纯 JavaScript 代码,就生成了视觉上高度接近的波点图案,展现了代码生成艺术的简洁与强大。 文章最终呈现的效果令人印象深刻,不仅是一个有趣的技术试验,也证明了用简单算法可以逼近复杂的艺术效果。文末还附上了社区用户更精确的实现方案,体现了技术实现的多样性与迭代可能。
建立动态规划状态转移方程的练习
这篇文章通过LeetCode上的八个经典题目,生动演示了如何攻克动态规划中最核心的一步:建立状态转移方程。作者从自身的复习笔记出发,挑选了Word Break、Unique Paths、Edit Distance等覆盖字符串、网格、树结构等多个领域的典型问题,逐一拆解其思考过程。 文章的核心观点是,解动态规划题的本质在于“状态识别”和“状态转移方程建立”这两步。像循环与递归的选择、空间换时间的优化,都只是实现技巧而非核心。例如,在解“三角形最小路径和”时,关键在于定义从底层向上积累的最短路径值f(i, k),并建立f(i, k) = min(下一层相邻状态) + 当前值的递推关系。对于“交错字符串”问题,则需定义f(i, j)表示两个子串前缀能否形成目标前缀,并据此建立逻辑或的转移方程。 作者没有停留在给出公式,而是试图还原每道题背后的状态定义逻辑。这种从具体例子提炼通用思考方法的叙述,让抽象的“建立方程”变得可触摸。对于正在学习动态规划的人来说,跟随这八个问题的思路走一遍,能有效训练如何从问题描述中提取状态,并找到状态之间递推关系的“感觉”。
Linux下互斥量加锁与解锁操作的C代码实现
这篇讲的是在多线程编程中如何安全地保护共享资源。作者从一个常见问题出发:当多个线程需要修改同一全局变量时,必须确保操作的原子性,否则容易引发不可预知的错误。 文章核心是演示一套完整的互斥量加锁与解锁C语言实现。作者没有停留在理论,而是直接给出了可运行的代码文件“LockAndUnlock.c”。其中,自定义的`MutexLock`函数封装了`pthread_mutex_timedlock`,并通过`gettimeofday`获取系统时间,巧妙地计算出带超时(5秒)的绝对等待时间,避免了线程可能被永久阻塞的风险。`MutexUnLock`函数则简洁地封装了解锁操作。 代码结构清晰,包含了宏定义、函数声明和完整的错误处理逻辑。文章最后还附上了在Linux下的具体编译命令(gcc -pthread)和运行结果,形成了一个从问题、方案到验证的闭环。对于需要在C程序中使用POSIX线程互斥机制的开发者来说,这套封装好的函数可以直接作为参考或API使用。