从现在起,请重视微博营销
作者从社会化营销的演进趋势出发,指出微博营销在企业整体策略中的地位正在变得愈发关键,特别是对于资源有限的中小企业而言。文章没有泛泛而谈方法论,而是直指微博营销的核心——它必须是一场“有人情味”的持续互动。 具体来说,作者强调成功的微博运营必须包含几个关键要素:营销行为要透出“人味”,而非冷冰冰的广告推送;要建立与用户的双向沟通,积极互动并真正关注粉丝的反馈;最后,这一切需要持之以恒地投入。文章的核心观点是,摒弃机械的广播式传播,回归以真诚互动和长期关系构建为基础的社交本质,才是微博营销的生命力所在。 这给运营者的核心启发是,在追求流量与转化的同时,必须重新审视与用户连接的温度。尤其对中小品牌,将微博视为一个与用户真诚对话、积累信任的社区,而非单纯的广告渠道,或许是用有限资源撬动长期价值的关键一步。
支撑起SNS的六度分隔理论和150法则
这篇从社交网络服务的基本概念讲起,重点剖析了两个支撑SNS发展的核心理论:六度分隔理论和150法则。 六度分隔理论指出,通过最多六个中间人就能连接任何人,这为社交网络的“可连接性”提供了理论依据。而150法则(或称邓巴数)则基于认知心理学,指出一个人能稳定维持的社交关系上限约为150人。文章深入对比了这两个理论的差异:六度分隔强调的是连接的“广度”与“可能性”,而150法则关注的则是关系维护的“深度”与“认知负荷”。 作者进一步将理论与实践结合,例如在分析Facebook早期设计时提到,其好友推荐与信息流设计,正是在利用六度分隔拓展网络的同时,又通过分组等功能试图帮助用户管理超出150人的社交压力。这揭示了成功的社交产品往往在“拓展连接”与“管理负担”之间寻找精妙的平衡。理解这两个基础模型,有助于我们看透SNS产品设计中“关系”与“信息”流动的底层逻辑。
算法的意义
作者从大学时期学习算法的经历出发,坦言自己是班上学得最差的那个,因为他总忍不住追问:“这个算法到底是为什么?” 而老师往往难以给出令他满意的回答。 这并非一篇传统的算法教程,而更像是在探讨算法学习的本质。它指出,许多人(包括曾经的老师)对算法的理解,可能还停留在“如何实现”的工具层面,而忽略了算法作为一种“思维方式”的核心意义——它如何抽象问题、权衡取舍,并最终优雅地解决问题。 文章的核心观点在于,理解算法背后的“为什么”,比单纯掌握其“怎么做”更为重要。这种追问驱动着学习者从机械记忆转向深度思考,真正领略算法设计中那种对效率与结构的极致追求。当我们开始思考“为什么”,算法就不再是课本上冰冷的伪代码,而成为了锻炼逻辑与洞察力的绝佳途径。
互联网对企业的意义
这篇讲的是2010年发表在《新营销》上的一篇旧文,原标题《互联网对企业的意义》在刊发时被编辑改为《互联网的营销意义》。作者自嘲起标题是弱项,但这个改动本身却折射出一个值得玩味的现象:即使在互联网已深度渗透的今天,我们依然容易不自觉地将“互联网”窄化为“营销工具”。 文章的核心在于从企业战略的视角重新审视互联网。作者跳出当时流行的“网络营销”框架,试图探讨互联网如何从组织结构、信息流动、客户关系乃至商业模式等多个维度,重塑企业的价值创造链条。比如,文中可能提及了内部协作效率的提升如何影响产品创新周期,或者直接对话用户的能力如何反向驱动供应链改造。 这种“文不对题”的遗憾,反而让文章多了一层元思考的意味:当我们谈论互联网时,究竟在谈论技术、渠道,还是一场深刻的生产关系变革?对于今天的读者而言,回看十多年前的这些思考,或许能帮助我们摆脱某些惯性思维,更本质地理解数字化浪潮下企业进化的真正驱动力。
基于关联规则的推荐系统
这篇讲的是基于关联规则的推荐系统。作者从关联规则的基本定义切入,清晰地阐述了
下载软件的专用地址生成方法
你是否好奇过,那些“迅雷专用下载”、“快车专用下载”的链接究竟是怎么生成的?这篇文章就为你拆解了其中的奥秘。 作者从 Base64 编码原理入手,手把手地带你看清了迅雷、快车、旋风这三种主流下载工具专用地址的“配方”差异。比如,迅雷地址是在原链接前后加上特定字符串后再进行 Base64 编码,而旋风的生成则更为直接。文章不仅给出了原理,更提供了每一步的具体转换示例和最终格式,可操作性很强。 学会这个,你不仅能轻松为自己的下载地址生成多种专用格式,还能起到一定隐藏真实链接的作用,可谓一举两得。
在linux系统中I/O 调度的选择
这篇文章聚焦于 Linux 系统中一个关键却常被忽视的环节:I/O 调度。作者将 I/O 调度算法比作磁盘 I/O 竞争中的“裁判”,其核心职责是在多个进程的读写请求中进行排序与调度,以优化整体性能。 文章围绕“如何选择”这一核心问题展开。它没有停留在调度算法“是什么”的泛泛介绍,而是重点剖析了不同算法的特性和适用场景。例如,对于像 SSD 这样的固态存储设备,简单的 NOOP 调度器(仅做请求合并)往往就能发挥最佳性能;而对于传统的机械硬盘,需要根据工作负载来选择:Deadline 算法能很好地平衡吞吐量与响应时间,避免请求饿死;而 CFQ(完全公平调度)则试图为所有进程分配公平的 I/O 带宽,更适合通用桌面或交互式环境。 文章的结论清晰直接:不存在一种适用于所有场景的“最佳”调度器。合理的 I/O 调度策略必须基于具体的硬件配置和应用程序的 I/O 特性(是顺序读写为主,还是随机小请求为主)来做出。理解这些选项之间的关键差异,是进行系统调优、确保应用在高负载下依然保持高效稳定的重要一步。
链轮策略:LinkWheel
这篇介绍的是SEO(搜索引擎优化)领域一种经典的外链构建策略——LinkWheel(链轮)。作者从提升网站权重的背景出发,解释了其核心思想:不再将所有的外部链接都指向同一个目标网站,而是创建一个由多个高质量、相关性强的独立页面(如博客、社交媒体资料页)组成的“轮形”结构。 具体来说,这个策略会将这些外围页面通过精心设计的内链或友链相互串联起来,形成一个闭环网络,然后每个外围页面再分别以不同的锚文本链接指向主站的目标页面。这样做的好处在于,它模拟了更自然、更多元化的链接来源模式,避免了大量外链直指主站可能引发的搜索引擎惩罚风险。 文章也指出,LinkWheel的关键在于每个外围页面本身也需要有足够的质量和原创内容,不能是空壳站。同时,它的构建成本较高,需要持续的内容维护,因此更适合作为针对特定高竞争关键词的长期优化策略,而非短期速成的手段。
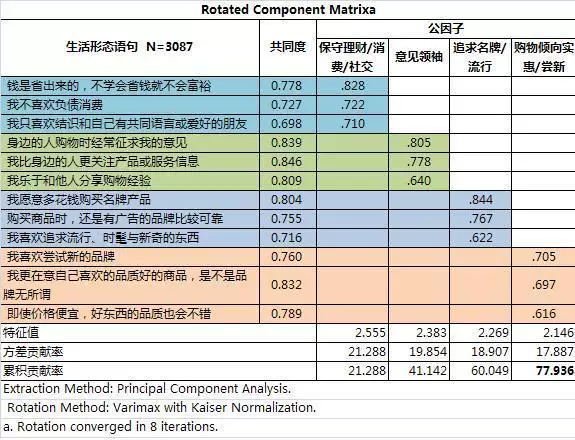
基于生活形态的用户分群研究
这篇探讨的是如何用“生活形态”这把尺子,更精准地丈量网络消费者的世界。文章指出,传统的人口统计学指标,如年龄、性别、收入,在解释消费行为上正显乏力。因此,需要从更深处切入——引入源自社会学与心理学的生活形态维度,去捕捉那些隐藏在数据背后的态度、价值观与决策动机。 作者从市场营销的经典理论出发,将其直接对准了网购迅猛发展的当下场景。文章的核心在于论证:购物网站要赢得未来,就不能仅停留在“用户买了什么”的表面数据,而必须深入“用户为何而买”的内在逻辑。通过剖析现有及潜在消费者的生活形态与消费观念,平台才能超越交易表象,真正洞察其价值诉求。 这意味着,分群策略将从冰冷的标签走向鲜活的生活图景。当理解了不同生活形态人群的深层动机,产品推荐、服务设计乃至品牌沟通,都能实现从“广撒网”到“精准共鸣”的转变。对于电商从业者而言,这无疑提供了一个从人性层面深挖用户价值、构建差异化竞争力的有力框架。
野兽渡河问题
这篇讲的是一个经典的逻辑谜题,但被巧妙地包装成了一个技术问题。它要求我们设计一套安全的渡河方案,让六只野兽——三对妈妈和孩子——过河。 问题的约束条件很有趣:只有大野兽会划船,船每次最多载两只,且任何时候都不能让小野兽在船上或河岸上“落单”(旁边有非妈妈的大野兽),否则它就会被吃掉。这实际上是在一个严格的规则网络下,进行路径规划。 文章的核心价值并不在于谜题本身有多新颖,而在于它清晰地拆解了这类问题的分析框架。它引导读者将复杂的互动关系转化为明确的“状态”(哪些野兽在哪一边),并推导出从初始状态到目标状态的每一步合法操作。这种将现实问题抽象为状态空间搜索的思维,和我们在做算法设计或系统架构时思考资源分配、避免死锁的逻辑是相通的。解决它需要的是严谨的步骤推演,而非灵感乍现。 作者通过这个趣味案例,展示的其实是一种解决多约束条件优化问题的通用方法:明确定义状态,穷举可能性,并用排除法规避危险路径。对于想锻炼逻辑思维的读者,这会是一次不错的思维体操。
Google Wave:入口的争夺
这篇讲的是Google Wave在2009年发布前夕引发的技术圈骚动。文章从两个具体现象切入:长达80分钟的产品演示赢得满堂彩,以及一个内测邀请码在eBay上被炒到上千美元。这勾勒出当时外界对这款产品的狂热期待。 作者的核心观点在于,这场狂欢的本质是互联网巨头对下一代“入口”的激烈争夺。Google Wave被视作一个野心勃勃的融合体,它试图将电子邮件、即时通讯、文档协作和社交网络无缝整合,从而统一用户在网络上的交互起点。文章分析认为,这种“全能型”设计体现了Google希望通过底层协议(如XMPP)和开放API来定义未来沟通标准的战略意图。 对读者而言,这篇文章的价值不仅在于回顾了一个经典产品的诞生,更在于揭示了一个规律:真正撼动行业的产品,往往始于对用户基础交互场景的重新定义。尽管Wave后来因复杂度过高而未能普及,但它对实时协作和开放生态的探索,深深影响了后来的许多工具。
[一道面试题]含有*的字符串匹配问题
这篇讲的是一道经典的算法面试题:LeetCode第10题“正则表达式匹配”。文章从问题本身出发,核心是拆解通配符 `*`(在题目中实际是点号 `.` 和星号 `*` 组合)匹配任意字符的逻辑。 作者清晰地梳理了解题思路,重点对比了动态规划与记忆化搜索两种方法。文章指出,动态规划虽然直观,但其二维状态空间需要 O(mn) 的时间和空间。而记忆化搜索本质上是递归加缓存,思路更贴合问题定义,通过自顶向下思考,可能避开一些不必要的计算。 文章的巧妙之处在于,最后引导读者思考:在已知上述方法复杂度后,能否进一步优化空间。这从解决单个问题提升到了对算法设计思维的探讨,展示了如何从正确解法走向更优解。对于准备算法面试或希望巩固动态规划思想的开发者来说,这是一篇逻辑清晰、有深入思考的技术解析。
计数和排序
这篇文章从一个关于“标准解法”是否令人满意的讨论讲起。作者最初看到一篇介绍程序技巧的文章,作者对给出的正确解法并不满意,认为那只是迫不得已的选择,期待未来更“真实”的结果。 但作者提出了截然相反的看法:他认为计算能力永远也追不上实际需求,我们会在越来越多的地方主动使用各种“有损优化”。这种优化并非妥协,而是像JPEG标准那样,在无伤大雅的前提下,智能地丢弃那些人难以察觉的细节,从而达成实用与效率的平衡。 文章的核心启发在于,它挑战了我们对“完美解决方案”的执念。在资源有限的现实世界中,这种“有损”的智慧,或许才是推动技术广泛落地和持续演进的关键。它引导读者思考:在追求绝对正确的“理想”与务实高效的“现实”之间,我们应如何做出权衡与选择。
小趣闻:STL的三个版本
这篇讲的是C++标准模板库(STL)历史中一个有趣的小插曲:在成为C++标准之前,STL其实有三个“有名有姓”的版本。作者从STL的早期历史讲起,梳理了HP STL、SGI STL和STLport这三个在社区中流传较广、影响深远的版本。 核心的差异点在于它们的出身、特性与应用场景。HP STL是最早的开源版本,由STL之父Alexander Stepanov和Meng Lee所在公司惠普发布,可以看作STL的“原始蓝图”。而SGI STL则是功能最为丰富、性能优异的版本,它不仅实现了标准,还加入了许多扩展,是许多编译器(如GCC早期版本)的底层选择。STLport则是为了跨平台兼容性而生的,旨在统一和规范不同平台上的STL实现。 对于开发者而言,了解这段历史并非只是为了怀旧。这三个版本分别代表了STL发展的不同侧重点:HP STL适合研究STL的初衷与设计,SGI STL是学习其内部实现和精妙算法的宝库(其代码注释尤其详尽),而STLport则展示了如何在不同系统环境中保证一致性。如今虽然它们大多被整合进了主流编译器的标准库,但这份梳理能帮助我们理解当前所用工具背后的思想传承。
动态数组的 C 实现
这篇讲的是在C语言中实现动态数组的过程。作者从“为什么标准C没有内置动态数组类型”这个基础问题出发,深入讲解了如何亲手构建一个可动态扩容的数组结构体。 文章的核心是实现思路:定义一个包含数据指针、当前长度和容量的结构体,并围绕它实现了init、push、pop等关键操作。巧妙之处在于扩容策略——当元素数量达到容量上限时,通过realloc将数组空间加倍,这种倍增策略有效平衡了频繁分配和内存浪费。作者还特别处理了内存对齐与指针迁移的细节,确保扩容后的内存连续性不受影响。 整体上,这篇文章把一个常见的数据结构拆解得清晰扎实,不仅展示了指针和内存管理的实战技巧,也体现了从底层构建可靠组件的工程思维。对于想透彻理解动态数组原理或在嵌入式等受限环境中自定义容器的开发者,这是一份非常实在的实现参考。
关键词工具整理
这篇讲的是如何系统梳理和比较各类关键词工具。作者从SEO从业者和内容创作者的常见需求出发,重点拆解了Google Adwords关键词工具这类核心工具的运作逻辑——它如何通过查询量、竞争度等指标,帮助用户定位潜在流量入口。 文章没有停留在罗列工具清单,而是进一步对比了不同工具在数据源、更新频率和使用场景上的差异。比如,有些工具更适合挖掘长尾词,有些则更擅长分析竞争对手的流量结构。这种对比直接指向一个实用问题:面对特定目标(如新品推广或内容规划),该优先选用哪类工具组合。 整体上,这是一篇工具指南,但更偏向于方法论的梳理。它帮你理解工具背后的设计思路,从而能更灵活地运用它们去解决实际工作中的关键词策略问题。
一致性hash算法
这篇讲的是一致性哈希算法,它最初是为了解决在动态缓存集群中,传统哈希算法因节点增减而导致大规模数据迁移的问题。想象一下,如果缓存节点突然增加或减少,传统取模哈希会让几乎所有请求都落到错误的节点上,造成缓存雪崩。 作者从这个经典痛点出发,介绍了一致性哈希的核心思想:它将哈希值空间组织成一个虚拟的环(通常称为Hash Ring),并让服务器节点和数据键都通过相同的哈希函数映射到这个环上。数据键被顺时针找到的第一个节点负责处理。这样一来,当增减一个节点时,只有环上相邻区间的少量数据需要迁移,影响范围被极大地最小化了。 文章还提到了为了解决节点分布不均可能带来的负载倾斜问题,引入了“虚拟节点”机制——每个物理节点对应环上的多个虚拟点,让负载分布更均匀。这套方案是许多分布式系统(如Memcached、Cassandra)实现高扩展性的基石。
string替换所有指定字符串(C++)
这篇讲的是如何在C++中实现字符串的全局替换功能。文章从标准库string自带的replace方法出发,点明了其局限性:它只能基于位置和长度进行替换,无法直接“找出所有指定子串并一一替换”。这其实是一个常见的编程需求缺口。 作者的核心思路是手动遍历和构建新字符串。通过循环查找目标子串的位置,每次找到后将之前的部分和替换结果拼接,然后更新位置继续向后查找,直到遍历完整个字符串。这个过程中需要注意更新查找起始位置,以避免陷入死循环或跳过重叠部分。 文章的价值在于它提供了一个清晰、可复用的实现模板,把看似繁琐的需求拆解成了几个关键步骤。对于经常处理文本解析或配置修改的C++开发者来说,这种手动实现的全局替换技巧,比依赖外部库更为轻便直接。
从140秒到2秒的优化
作者从处理海量数字去重的场景切入:面对2亿个0到20亿之间的随机数字,需要统计其中的不重复记录总数。最初的思路是使用 Bloom Filter,但考虑到数据类型纯粹为数字,Bloom Filter 的开销显得偏重,于是转而采用更轻量级的 bitarray(位数组)来实现。 第一个版本基于 bitarray 的实现将处理时间从原来的 140 秒大幅压缩到了 2 秒。这种优化选择非常关键,因为它充分利用了数字数据的特点,用一个比特位直接映射一个可能的值(0 到 20 亿),从而在内存效率和速度之间取得了极佳的平衡。文章通过这个具体的优化案例,展示了如何根据数据特征选择合适的数据结构,对于处理类似的大规模数字去重或查找问题提供了直接的实践参考。
倒置字符串中的单词
这篇讲的是一个经典字符串处理问题——如何高效地倒置句子中的单词顺序,比如将“Hello World”转换为“World Hello”。作者从编程面试和日常数据清洗场景切入,深入剖析了两种核心实现方案:基于栈的临时存储法和利用双指针的原地反转法。 栈方案通过遍历字符串将单词压栈再弹出,逻辑直观,但需要O(n)的额外空间;而双指针法则通过先整体反转整个字符串,再逐个反转每个单词的方式,实现了原地操作,将空间复杂度优化至O(1)。文章特别强调了双指针法中的巧妙之处:如何在反转过程中准确识别单词边界