xdebug 配置,在这里备份下
这篇讲的是作者对自己常用Xdebug配置的一次快速备份。内容非常直接,没有复杂的原理分析或故障排查故事,就是一个“以防下次麻烦,先存好再说”的实用举动。 虽然作者自己调侃“似乎也没啥好备份的”,但这种日常的、看似琐碎的配置记录,恰恰是很多开发者工作流程中的一个缩影。对于那些正需要搭建或优化PHP调试环境的开发者来说,看到这样一份现成的、经过验证的配置片段,或许能省去一些从零开始摸索的时间。文章没有展开配置的每一项细节,其价值更像一个起点或参考,提示你可以在此基础上根据自己的项目需求进行调整。
perl的格式化(Format)报表输出
这篇讲的是Perl语言里一个特别而实用的小功能:格式化报表输出。众所周知,Perl在文本数据处理上非常强大,而这个内置的格式化功能,则能让它在命令行下轻松生成结构化的报表或简单图表。 实现过程并不复杂,核心在于三步:先以关键字`format`声明一个格式,接着创建与该格式绑定的文件句柄,最后通过`write`命令来执行输出。整个“报表”的样式由`@`、`^`、`<`、`>`、`|`等特殊符号精确定义,它们能规划出每一行的外观,比如字段的位置和对齐方式。之后,将具体的数据项按顺序填充进去,一个格式化的数据视图就呈现出来了。 相比于复杂的图形工具,这种方法提供了轻量级的解决方案,尤其适合那些需要快速将数据整理成可读行列的场景。它展示了Perl如何用简洁的语法解决实际的数据呈现问题,是 Perl 工具箱里一件低调但趁手的兵器。
perl的expect使用方法,实现非交互式登录。
这篇讲的是perl的expect工具在实现非交互式登录中的应用。作者从自动化脚本的实际需求出发,聚焦于expect这个能处理交互式会话的模块,如何与perl结合来模拟用户输入,从而绕过手动登录步骤。 文章先解释了expect的基本原理:它通过预测程序的输出来自动响应提示,比如密码询问或菜单选择。在perl中,通常通过Expect.pm模块来集成,核心思路是建立连接、发送命令、匹配预期输出并自动回复。具体到非交互式登录,文中可能展示了代码示例,包括如何设置超时、处理错误反馈,以及确保连接的安全性。 关键差异在于,相比传统的SSH密钥认证或直接脚本调用,expect更擅长应对那些需要动态交互的场景,比如老旧系统或特定命令行工具。它能灵活适应不同的提示格式,但使用时也需注意避免硬编码敏感信息。文章通过实际用例,比如批量管理远程服务器,说明了这种方法的效率——登录过程从分钟级缩短到秒级,减少了人为干预的错误。 整体来看,文章没有停留在概念层面,而是紧扣实现细节,帮助读者快速上手。对于需要自动化运维或测试的开发者来说,这是一种实用且可靠的技术路径。
Perl 倒行分析文件方法。perl读文本文件,从末尾往前读.
这篇讲的是一个实用的 Perl 技巧,专门解决如何高效地从文件末尾向前读取内容的问题。作者直接给出了一个核心方案:使用 CPAN 上的 File::ReadBackwards 模块。 在处理日志文件或大型文本时,我们常常需要从后往前查看最近的错误或信息。常规的文件读取方式是从头开始,若文件很大,效率低下且不切实际。而 File::ReadBackwards 模块则彻底改变了这个过程。它允许你像倒着翻阅一本书一样,逐行地、高效地从文件的末尾开始读取,非常适合进行日志分析或处理那些只需关注尾部数据的场景。 文章简洁地展示了模块的用法,并附上了 CPAN 上的官方文档链接,方便读者深入查看安装方法和更多示例。对于 Perl 开发者而言,掌握这个模块能让你在处理特定文件任务时事半功倍。
Perl闭包实例解释
这篇讲的是 Perl 闭包的概念与具体应用。文章没有停留在理论定义上,而是直接通过一个简洁的错误消息处理函数 `errorMsg` 的实例,来演示闭包如何工作。 核心在于,`errorMsg` 子程序返回的并非普通值,而是一个匿名子程序。这个内部子程序“记住”了被调用时传入的 `$lvl` 变量值——即使外部 `errorMsg` 执行完毕,这个值依然被内部子程序所引用,这就是闭包。 代码展示了三个不同的错误级别(Severe、Fatal、Annoying)如何通过同一个工厂函数生成,并且每个生成的闭包都独立地封装了自己的级别参数。当调用 `$severe`、`$fatal` 等变量指向的闭包时,它们能准确输出对应的级别信息。 通过这个实例,文章清晰地传达了闭包的关键特性:**它允许函数捕获并持续拥有其词法作用域内的状态**。这种特性非常适合用于创建可配置的回调函数、工厂模式以及任何需要“记住”某些上下文状态的场景,为代码提供了更高的灵活性和封装性。
利用开源的Gearman框架构建分布式图片处理平台[原创]
这篇分享来自2009年金山逍遥技术团队的内部交流,聚焦于他们如何使用开源的Gearman框架,从零构建起名为DIPS的分布式图片处理平台。 文章的核心是解决一个具体的生产问题:如何应对日益增长的、高并发的图片处理请求,实现任务的高效分发与并行处理。作者团队选择了轻量级的分布式任务队列框架Gearman作为技术基座,详细介绍了从架构设计到落地实施的完整过程,包括如何利用Gearman的Worker机制将计算任务分发到多个节点,从而水平扩展图片处理能力。 文中通过一系列PPT清晰地展示了DIPS的整体架构与工作流,体现了如何借助开源工具快速搭建出稳定、可扩展的后台服务系统。对于关注分布式计算早期实践,或需要构建类似异步任务处理系统的开发者而言,这篇回顾提供了具体的架构思路与落地经验。

PHP版的slow-query
开发者调试PHP性能问题时,常常需要一种直观的方式定位那些“不声不响”却执行缓慢的脚本,而这正是MySQL中`slow_query_log`试图解决的问题。这篇讲的是作者从相似思路出发,开发了一个名为slowphp的PHP扩展。 这个扩展的核心功能很简单:记录Web服务器上执行时间超过设定阈值的PHP脚本。它的实现很巧妙,直接作为PHP扩展来工作,这意味着它能以较低的性能开销,精准地捕获运行慢的脚本路径和执行时间。作者刻意模仿了MySQL慢查询日志的用法和输出格式,让任何熟悉数据库性能调优的开发者都能立刻上手。 对于需要快速搭建应用性能监控(APM)基础,或者苦于没有轻量级工具来发现PHP代码瓶颈的团队来说,这个思路提供了一个具体可落地的方案。它把数据库领域已验证的有效诊断方法,成功移植到了Web应用层面。
整理了一份招PHP高级工程师的面试题
这篇文章汇总了一套针对PHP高级工程师职位的面试题,核心目的是通过一套精心设计的题目,快速鉴别候选人的技术深度与解决实际问题的能力。作者认为,能较好地回答这些问题,往往意味着具备了相应岗位所需的关键素质。 面试题覆盖了多个进阶方向,而不仅仅是基础语法。例如,它会深入考察对PHP底层原理的理解,比如内存管理、垃圾回收机制,以及Zend引擎的工作方式。此外,题目还着重考察了对现代PHP生态的掌握,包括Composer的深度使用、性能剖析工具(如Xdebug、Tideways)的应用,以及如何设计高并发场景下的缓存策略。其中一些题目会模拟真实的线上故障,要求候选人描述排查思路与解决步骤,这直接关联到工程师的实战经验与临场应变能力。 这套题的设计逻辑清晰,它将知识广度、原理理解与实战能力紧密结合。对于招聘方而言,它是一个高效的评估工具;对于开发者自己,则可以作为一个清晰的自查清单,用来审视自己在高级技术栈上的积累是否扎实,是否存在需要补强的短板。
c/c++访问超过2G的文件
这篇讲的是在Windows平台用C/C++处理大文件时一个经典且容易被忽略的“坑”。作者从实际开发经历出发,记录了当使用标准库函数(如`fopen`)打开或操作超过2GB(甚至4GB)大小的文件时,程序可能意外失败或数据错位的故障现象。 其根本原因在于,Windows下32位应用程序的标准文件操作函数和底层文件偏移量类型(如`long`或`size_t`)通常被限制在32位,最大只能表示约2GB或4GB的地址空间。一旦文件体积超过这个界限,传统的读写位置计算就会发生溢出,导致不可预知的行为。 为了解决这个问题,文章指向了正确的方法:使用专为大文件设计的API,例如`_fseeki64`、`_ftelli64`以及`__int64`(或更现代的`int64_t`)来处理文件偏移量。在二进制模式下打开文件,并使用这些64位函数,才能让程序突破容量限制,可靠地访问海量数据。对于需要处理大型数据集、日志或媒体文件的开发者而言,这是确保程序健壮性必须掌握的一个基础知识点。
TCP连续发送N份小数据
这篇文章深入讲解了TCP协议中一个常被忽略的细节:delayed ack(延迟确认)机制。当接收方连续收到多份小数据时,它不会为每个数据包立即发送ACK确认,而是倾向于等待一个短暂的超时窗口(例如200ms),或者直到有数据需要回写发送方时,才将ACK搭车一并发出。这种处理方式与传统的立即ACK形成了鲜明对比——后者会为每个数据段单独发送确认,虽然响应快,但容易在网络中产生大量小包,增加拥塞风险。delayed ack通过合并确认来优化效率,尤其适合高吞吐量场景,比如文件传输或视频流,它能有效减少网络开销并提升整体性能。不过,在延迟敏感的应用中,如在线游戏或实时通信,过长的ACK延迟也可能拖慢交互速度。通过理解这一机制的原理和适用边界,开发者可以更精准地调优TCP连接,在可靠性和效率之间找到平衡点。
Content-Type问题总结
这篇讲的是一个在Web开发中经常被忽视但影响重大的细节:Content-Type响应头。 文章从一个典型的问题场景切入——浏览器没有按预期展示服务器返回的数据。比如,明明拿到了JSON格式的数据,却无法用JavaScript正常解析,或者一张图片在页面上只显示为一堆乱码。其根本原因就在于,服务器在发送内容时,没有在HTTP响应头中正确设置Content-Type字段,告诉浏览器“我即将发送的是什么类型的内容”。 作者深入剖析了Content-Type的作用机制,它本质上是服务器与浏览器之间的一份“内容说明书”。文章对比了几种常见场景:当发送JSON数据时,正确的`Content-Type: application/json`能让浏览器调用JS引擎处理;对于普通文本,`text/plain`会将其原样呈现;而对于图片,则需要`image/png`或`image/jpeg`这样的标识。如果设置错误或缺失,浏览器只能依赖自身猜测,极易出错。 文章的价值在于,它不仅指出了问题,更清晰地解释了每种常见类型值的具体含义和适用情况,帮助开发者从“知道要加这个头”提升到“理解为什么以及何时用哪个”。这个看似微小的配置,却是保障前后端数据顺畅交互、避免莫名其妙前端Bug的基础一环。
xdebug: var_dump函数设置
这篇讲的是如何利用 xdebug 让 PHP 原生的 `var_dump` 函数输出变得更易读。安装 xdebug 后,它会自动“接管”你原本的 `var_dump`,瞬间改变数据结构的展示方式——嵌套数组和对象的层级会变得清晰,不同类型的数据拥有对应的色彩和明确标识,深度递归也不会轻易把页面撑爆。 这种“增强版 var_dump”对调试复杂数据结构尤其友好。相比原始输出常因缺乏格式而难以扫视,xdebug 的版本会帮你自动格式化、区分标量与复合类型,让开发者能快速定位数据异常。无论你是刚接触 PHP 调试,还是经常需要处理多维数组,启用 xdebug 后的 `var_dump` 都能让日常开发中的变量检查环节变得更直观。
curl 命令使用cookie
这篇讲的是用curl处理HTTP Cookie的实战技巧。作者从最常见的爬虫或接口调试场景出发,解释了Cookie在维持登录状态、处理会话中的关键作用,并直指核心:如何让curl像浏览器一样自动保存和发送Cookie。 文章没有停留在理论,而是深入演示了两种核心用法。一种是手动指定 `-b` 参数来发送已知的Cookie字符串,适合单次请求调试。另一种更强大的是通过 `-c` 参数让curl自动将服务器返回的Cookie保存到本地文件,之后用 `-b` 读取该文件,就能模拟连续的会话,比如模拟登录后访问需要权限的页面。作者还对比了 `-L`(跟随重定向)与 `-c` 配合使用的细节,指出在登录后跳转的场景下,必须先保存中间步骤的Cookie才能最终成功,这是很多人会踩的坑。 最后,文章提到了一个容易被忽略的要点:curl保存的Cookie文件是Netscape格式,与浏览器格式不通用,但可以直接被后续的curl命令识别。整个讲解从问题切入,对比了不同参数组合的适用场景,把看似简单的 `-b/-c` 选项背后的逻辑讲透了。
lihttpd ssl 配置
这篇讲的是如何在Windows系统中为lighttpd服务器配置SSL证书,让网站支持HTTPS加密访问。作者从实际部署需求出发,详细记录了在Windows环境下从零开始生成证书、修改lighttpd配置文件、到最终成功启用SSL的全过程。 配置过程涉及几个关键步骤:首先需要生成或准备有效的SSL证书和私钥文件;接着在lighttpd的配置文件中指定证书路径,并监听443端口;同时还要处理常见的权限问题和配置语法检查。文章特别提到了Windows与Linux在文件路径和权限管理上的一些差异,这对习惯Linux环境的开发者来说是值得注意的细节。 通过具体配置示例的演示,文章展示了如何让lighttpd正确加载证书并建立安全连接。作者最后验证了配置效果,确认服务器可以通过HTTPS协议正常响应请求。对于需要在Windows平台上快速部署轻量级加密Web服务的开发者,这些实操步骤提供了清晰的参考。
base64_encode 和 urlencode
这篇文章探讨了一个常见但容易被忽略的技术细节:为什么 base64 编码不适合作为 URL 编码使用。 作者从 base64 编码被广泛用于网络传输这一现象切入,指出很多人因为它生成的字符相对“安全”(主要是 ASCII 字符),就直接将其用于 URL 参数中。文章深入解释了 base64 和 URL 编码(如 `urlencode`)在设计目的上的根本差异。base64 主要是为了将二进制数据转换为 ASCII 文本以适应纯文本传输渠道,而 URL 编码则专门针对 URL 语法中具有特殊含义的保留字符(如 `&`, `=`, `?`)进行转义,以确保整个 URL 结构的完整性。 文章的核心论点在于,混用这两种编码会带来潜在风险。例如,base64 编码结果中可能包含 `+` 或 `/` 等字符,这些在 URL 中具有特殊语义,会导致解析错误或安全漏洞。最后,文章给出了明确的实践建议:在处理 URL 参数时,应使用专门的 URL 编码函数;而对于需要安全传输的二进制或结构化数据,则应优先考虑 base64 编码。这篇短文对开发者来说是一个及时的提醒,能帮助避免在数据传输层埋下隐患。
可恶,被 PHP-Mcrypt 的官方 Example 误导了
作者在为项目寻找轻量级的PHP对称加密方案时,采用了官方mcrypt模块的示例代码,却遇到了加密数据无法正确解密的诡异问题。深入排查后,他发现根源在于官方Example本身的一个关键疏漏:示例没有明确指定字符串与密钥的字符编码。 核心症结在于,PHP内部的字符串处理依赖于字符编码。当加密与解密过程编码不一致(例如,示例中可能混用了UTF-8与ISO-8859-1),就会导致加密后的数据在解密时因编码不匹配而彻底损坏。作者最终发现,显式统一使用UTF-8编码进行加密与解密,问题迎刃而解。 这个案例提醒开发者,在处理加密时,不仅要关注算法本身,更要对数据的“表示形式”(如字符编码)保持高度警惕。官方文档的示例有时为了简洁可能会忽略这类前提条件,在实际生产环境中直接照搬,很可能就会掉进类似的陷阱。
ZFS性能的一些优化结论
作者最近针对ZFS在大规模磁盘环境下的性能表现进行了一系列实测,测试环境配置了24块硬盘组成的JBOD(Just a Bunch of Disks),其中包含2块热备盘。文章聚焦于在这样盘数较多的复杂存储场景下,ZFS文件系统所呈现出的性能特点与优化方向。 测试过程很可能深入探索了ZFS在高并发、大数据量读写场景中的瓶颈,例如其自适应替换缓存(ARC)的行为、数据条带化的分布策略,以及RAZ组配置(如RAIDZ1/2/3)对整体吞吐和延迟的影响。作者从实际测试数据出发,给出了在多盘场景下的一些关键优化结论,这些结论可能涉及如何合理设置异步IO数量、调整脏数据写回阈值,或是优化元数据加载方式,旨在帮助读者在类似硬件配置下压榨出存储系统的最佳性能。 对于正在搭建或优化基于ZFS的存储解决方案(特别是使用大量磁盘构建高容量存储池)的工程师和架构师来说,这篇分享提供了来自实战的一手观察与调整思路。文章结论直接关联到具体参数调整,可为实际部署提供有价值的参考。
DMA设备驱动的常见问题
这篇讲的是DMA设备驱动开发中那些让人头疼的常见“坑”。文章从DMA(直接内存访问)这项能显著提升系统并发能力的技术出发,直指它在具体实现时的复杂挑战。 作者梳理了开发者在实际工作中最常碰到的问题类型。比如,如何正确进行内存映射以避免数据错乱,如何处理缓存一致性问题来保证数据完整性,以及在中断与轮询间如何权衡以优化性能。文章没有停留在现象描述,而是深入分析了每个问题背后的硬件交互机制和软件设计考量,揭示了这些“坑”的根源往往在于软硬件理解的不对等。 它提供了一套从问题现象到本质分析的思路。例如,一个数据损坏的问题,可能追溯到未正确设置内存屏障或忽略了CPU缓存的影响。通过这样的剖析,文章将零散的故障点串联成了系统性的知识,帮助开发者理解为什么某些配置是必须的,而不仅仅是记住操作步骤。 对于正在与DMA驱动打交道的工程师来说,这篇文章更像是一份避坑指南和设计自查清单,有助于在底层细节上建立起更扎实的认知。
操,中国电信!
这篇讲的是作者从自家电信宽带的日常使用体验出发,对“电信服务差”这个普遍印象的重新审视与思考。 作者坦承,以往主要从网络上的抱怨中感知电信的负面形象,但因为自家宽带仅用于偶尔值班,且不进行大流量下载,实际上并未亲身经历明显的网络问题。这促使他产生了一个疑问:电信的服务是否真如舆论所言不堪? 为一探究竟,他尝试了升级方案——将光猫从百兆更换为支持千兆的型号,并在光猫后台开启了相应设置。然而,后续测试发现,网络配置上可能仍存在限制。这次动手实践揭示了一个更关键的因素:即便硬件设备升级,如果网络配置策略(如限速、端口绑定等)或物理线路质量(如网线、接头、入户线缆)存在问题,最终体验依然会大打折扣。 因此,作者的核心观点是,对网络质量的评判不能简单归咎于服务商“一刀切”,实际效果往往是硬件、配置与线路质量共同作用的结果。他的经历提醒我们,在排查网络问题时,需要综合考量多个环节。
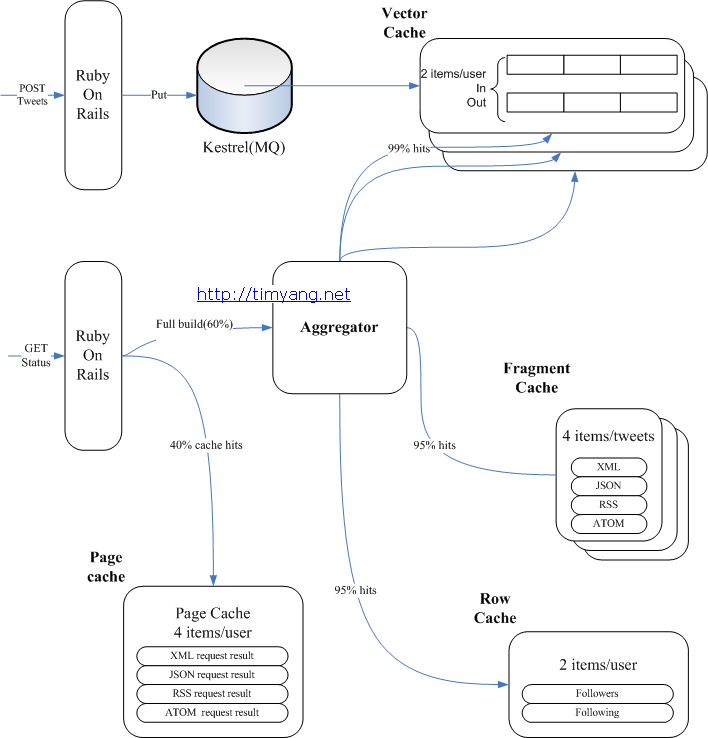
Twitter架构图(cache篇)
这篇内容从Twitter公开资料出发,梳理了其缓存架构的设计思路。作者重点解决的是如何在高并发场景下,通过缓存系统有效减轻数据库压力并提升响应速度。 文章的核心方案围绕多层缓存架构展开。作者分析了Twitter如何将本地缓存与分布式缓存(如Memcached集群)结合,形成“请求-本地缓存-远程缓存-数据库”的漏斗模型。同时,针对热点数据问题,介绍了通过“缓存预热”与“热点键发现”机制来优化访问路径。文中还提到了数据分片策略对缓存集群横向扩展的关键作用,以及序列化协议选择对性能的影响。 基于现有信息,作者推测这套架构帮助Twitter在流量高峰时将读请求延迟控制在较低水平,并支撑了其亿级用户的动态信息流。尽管这是基于公开资料的推测与补充,但对理解大规模系统如何设计缓存层,提供了非常具体的参考视角。