以keystore方式为play!应用建立单向/双向SSL
这篇讲的是如何在Play!框架中配置SSL安全连接,而且特别澄清了官方文档的不足之处,避免读者被过时资料误导。 作者先理清了SSL的核心:用对称加密传输数据,非对称加密(RSA)安全传递密钥。在此基础上,解释了单向SSL(服务端验证)和双向SSL(服务端与客户端互相验证)的区别,后者适用于需要严格控制访问权限的内部服务。 配置的关键在于正确设置keystore。文章详细演示了生成服务端密钥库(certificate.jks)的命令,并特别指出密钥库口令与密钥口令必须一致这个容易忽略的坑。对于单向SSL,配置到此即可。 如果需要双向SSL,流程还涉及在客户端生成并导出证书,然后将该证书导入服务端的密钥库进行“授信”。整个过程通过具体的keytool和openssl命令逐步拆解,甚至涵盖了使用curl和浏览器进行测试的不同方法,非常实操。 文章用清晰的步骤,把Play!应用如何建立从单向到双向的SSL连接,从原理到命令都讲透了。
Nginx与Gzip请求
这篇讲的是Nginx如何处理客户端发来的Gzip压缩请求。作者从移动端同事的需求出发——为了节省流量和提升传输速度,需要让服务端解压缩客户端发送的Gzip数据。但Nginx自带的Gzip模块都是处理响应(Response)的,对于请求(Request)的解压缩并无直接支持。 文章详细探索了两种可行的技术方案:一是使用lua-zlib库直接解压;二是通过LuaJIT的FFI接口封装系统的zlib库来实现。作者不仅给出了具体的代码示例,还贴心地解决了在Linux环境下可能遇到的动态库加载路径不匹配的问题。最后,文章在PHP后端架构下进行了测试,对比了两种方案的性能,发现lua-zlib的效率反而略高于理论上更优的FFI方案。 核心结论是,借助OpenResty和Lua的强大扩展能力,可以在Nginx的access阶段灵活处理特殊的压缩请求,为异构系统(如PHP后端)解压数据,是一个高效且实用的解决方案。
Nginx HttpMemcModule和直接访问memcached效率对比测试
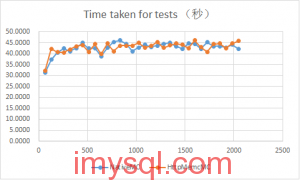
这篇实测对比了两种访问memcached的方式:通过Nginx的HttpMemcModule模块代理,以及由PHP直接连接。作者搭建了具体的测试环境,使用不同配置的服务器,从64到2048的并发线程发起压力测试。 测试揭示了几个关键差异。首先,在效率上,即使经过优化,通过Nginx HttpMemc代理的平均效率大约只有直接访问的72.6%左右,存在一定的性能损失。但更重要的是稳定性:直接连接memcached时,失败的请求数会显著增加,而借助HttpMemc模块(并配置了keepalive),连接失败的情况得到明显改善。 文章还补充了调整TCP内核参数(如开启tcp_tw_recycle和tcp_tw_reuse)后的测试结果。调整后,不仅失败请求完全归零,整体TCP效率也得到提升。最终结论是,尽管HttpMemc模块会带来一些性能损耗,但其在连接复用和对上层应用透明方面的优势,使得这个损耗在可接受范围内,尤其是在需要高连接稳定性的场景下,它依然是一个值得考虑的方案。
关于socket这个术语的来源
这篇讲的是“socket”这个在编程中无处不在的术语,究竟是从哪里冒出来的。作者从大家熟悉的中文译名“套接字”和“插口”入手,追溯了这个术语的权威出处。 文章引用了两本经典著作的不同视角:《Java TCP/IP Socket 编程》从应用编程接口的角度,强调socket是让程序通过网络互通的关键抽象;而《TCP/IP详解》则直接指出了它的技术本质——一个IP地址加一个端口号,并明确其来源是RFC793这份最早的TCP规范文档。 最硬核的部分是文章贴出了RFC793中对socket的原始定义。这里清楚地说明,socket是为了解决“单台主机上多个进程如何同时使用TCP”这个问题而设计的。一个socket(由网络地址和主机端口组合而成)可以被多个连接复用,这个设计思想一直沿用至今。 所以,这篇文章不仅仅是解释一个名词,更是一次对网络编程基石概念的考古。它把我们日常使用的工具,与几十年前协议设计者最初的那个简洁而巧妙的构想连接了起来。
网络传输协议AMF初探
这篇讲的是 AMF(Action Message Format)协议,一种专为高效数据传输设计的二进制格式。与传统的 SOAP/XML 文本传输方式不同,AMF 采用二进制编码,能高度压缩数据,特别适合传递大量资料——数据量越大,传输效率优势越明显。文章梳理了 AMF 的核心特点:它可以直接传输 Flash 内置对象(如 Object、Array、Date),服务器端能自动解析,大幅简化开发流程。 作者从 Flash Remoting 的实际选择出发,对比了 AMF 与 SOAP 的关键差异。AMF 不仅比冗长的 XML 更高效,而且因为它专注于支持 ActionScript 数据类型,在浏览器中体积仅需约 4KB(压缩后),而 SOAP 则庞大得多,且存在头部请求不支持的问题。文章还列举了 AMF 协议支持的数据类型及其对应的十六进制值,展示了其结构的紧凑性。 在实现层面,文章介绍了 AMF 基于 HTTP 的典型处理流程:从客户端请求、反序列化、服务处理到响应序列化,并提及 PHP、.NET、Python、Ruby 等主流语言都已拥有成熟的 AMF 框架(如 AMFPHP、FluorineFx),开发者可以快速实现 Flash 与后端数据库的通信。 总的来说,这篇文章清晰地说明了 AMF 如何通过二进制优化和对 Flash 生态的专注,在特定场景下(尤其是需要高效、轻量交互的 Web 应用中)成为比 SOAP 更具优势的选择。
阅读.NET源代码那些事
这篇讲的是如何通过直接阅读.NET框架源代码,来深入理解其内部实现机制。作者以自己在项目“Tmc”中借鉴BCL代码的经历为例,指出虽然.NET大部分组件不开源,但微软已公开了参考源代码库,并保持与版本的同步更新。 文章重点对比了反编译工具(如.NET Reflector)与直接阅读源代码的差异。作者指出,反编译会丢失变量名、注释等关键信息,而源代码中保留的详细注释,例如Hashtable实现中关于哈希算法选择的说明,更能清晰揭示设计思路和实现背景。 作者还通过Dictionary类的代码实例,揭示了一个巧妙的实现细节:在特定编译条件下,当插入操作的哈希碰撞次数超过阈值,Dictionary会随机化其比较器。这一机制正是为了应对曾引发安全关注的哈希碰撞DoS攻击,展现了框架在安全与性能上的权衡。 最终,作者将这些源于阅读源代码的经验应用到自己的项目中,通过参考和修改BCL代码来构建自定义的HashDictionary,证明了这种方法在提升代码质量与理解深度上的直接价值。
erlang和其他语言读文件性能大比拼
这篇讲的是不同语言在处理大文件读取时的性能较量,主角是Erlang。作者从公司一次技术比武的真实案例出发——有同事用Erlang处理1.1GB文本的词频统计耗时55秒,而用C只需2.6秒,Java为3.2秒——引出了一个普遍疑问:Erlang读文件真的这么慢吗? 为了重新验证,作者准备了一个1GB的测试文件,详细对比了多种读取策略的性能。数据很有说服力:在单线程缓冲读取模式下,Erlang耗时0.322秒,与C语言的dd命令(0.264秒)处于同一量级;而启用多线程并发读取后,耗时缩短至0.214秒,性能甚至超越了C语言。但反例也很明显,如果以4KB小块读取,耗时会骤增至3.56秒,性能急剧下降。 文章揭示了性能差异背后的核心机制:Erlang的文件IO通过efile驱动实现,本质是轻量级的C封装,但每次操作都涉及“发消息→驱动执行→等待结果”三个阶段。这种设计在IO操作粒度过小时,消息传递开销会被放大,违背了Erlang“小消息,大计算”的原则。因此,性能的关键在于使用大块缓冲区读取,并充分利用异步线程池并行化IO,从而将Erlang的IO性能推到理论极限。
遭遇php的in_array低性能
这篇讲的是 PHP 中 `in_array` 函数的一个性能陷阱。作者从一次真实的接口优化经历出发,发现将重复的缓存读取移出循环后,接口响应时间虽从 5 秒降至 2 秒,但仍未达到预期。通过编写测试代码重现,问题被定位到 `in_array` 函数本身。 性能杀手在于 `in_array` 默认的“松散比较”模式。当数组元素和待查找值均为“字符串型的数字”时,PHP 引擎会尝试将它们转换为长整型再进行比较。这个过程中频繁调用 `strtol` 系列库函数,消耗了大量时间,导致仅 3000 次循环就耗时超过 1 秒。 解决办法很简单:为 `in_array` 添加第三个参数 `true`,启用严格比较模式,同时比较值与类型。这避免了 PHP 内部不必要的类型转换,性能因此提升数倍,测试用例的执行时间从 1.132 秒骤降至 0.267 秒。文章通过 `strace` 和 `ltrace` 工具深入剖析了问题根源,对于处理大量数据的 PHP 开发者而言,这是一个值得警惕的细节。
闲扯Nginx的accept_mutex配置
这篇闲扯文章深入探讨了Nginx中一个常被忽略却影响吞吐量的配置——accept_mutex。文章从它的基本作用说起:启用时,新连接到达只会唤醒一个worker来处理,从而避免“惊群问题”;禁用时则所有worker都会被唤醒,虽可能导致性能损耗,但Nginx作者Igor Sysoev指出,由于Nginx的worker进程通常较少(几十个),惊群影响其实有限。 文中对比了启用与禁用accept_mutex的场景:启用更像“主动喂小鸡”,在资源稀缺时(如连接数少)高效且稳定;禁用则像“撒粮让鸡抢”,当访问量大时能提升整体吞吐量,尽管可能增加上下文切换(可通过sar -w观察)。作者引用Igor Sysoev的解释,强调这与Apache(动辄上百进程)不同,Nginx因进程少而更灵活。 基于这些分析,文章最终建议:对于高流量网站,关闭accept_mutex是值得考虑的优化选择,以平衡惊群风险与系统性能。整体从具体配置出发,用生动比喻和权威引用,提供了清晰的实践指导。
在线状态服务在网站系统中的应用
这篇讲的是如何为一个百万级同时在线、日均亿级PV的网站构建高效的在线状态服务。作者从前篇Facebook聊天架构分析中提取出“在线状态服务器”这一通用模块,指出在普通网站中,它主要维护用户活跃列表,通常通过客户端定时发送心跳包来实现。 挑战在于,当用户量巨大时,服务需要承受极高的心跳包请求压力。文章对比了三种实现思路:最常见的PHP+MySQL方案会因数据库成为瓶颈;改用Redis虽能缓解存储压力,但PHP本身处理能力有限;最终,作者提出用C/C++开发专用HTTP服务器,整合精简协议处理与高速内存数据结构,结合libevent等库,有望在单机上轻松达到每秒万级请求的处理能力。 文章从实际性能瓶颈出发,逐步推导出一个针对性的技术方案,不仅分析了不同技术栈的优劣,也给出了具体的性能预期。文末作者还邀请有兴趣的开发者一起交流实现。
Linux内核协议栈对于timewait状态的处理
这篇文章从一次生产环境的运维问题切入,详细剖析了Linux内核从2.6.18升级到2.6.32后,系统TIME_WAIT状态连接数显著增多的根因。作者的核心工作是对两个版本内核的代码进行diff,精准定位到了`net/ipv4/inet_timewait_sock.c`文件中的一处关键变更。 问题的核心在于`inet_twdr_hangman`函数里,一行负责轮转回收槽位的代码`twdr->slot = ...`的位置被移动了。在旧版本中,无论当前槽位(slot)的timewait块是否被完全清理,该自增操作都会执行;而在新版本中,它被放入了一个条件分支,仅当当前槽位被成功清空时才执行。这个看似微小的时序调整,改变了内核回收timewait块的调度逻辑,最终导致了回收变慢和积压。 文章不仅给出了结论,更通过分析`inet_timewait_death_row`数据结构与`inet_twdr_hangman`的定时回收机制,完整还原了问题发生的底层路径。对于需要理解TCP连接生命周期管理,或是面临类似内核升级后网络连接数异常的工程师来说,这篇深入源码实现的排障手记提供了非常具体的思路和技术细节。
你应该更新的Java知识之Optional
这篇讲的是Java中一个常见却恼人的痛点:空指针异常(NPE)。作者从“Null Sucks”这句名言切入,指出传统上为了防御NPE而编写的判空代码,不仅冗余,还极易因疏忽而遗漏,导致程序崩溃。 文章的核心是介绍一种更优雅的解决方案:Optional。它并非简单替代if-null检查,而是通过封装可能为null的对象,强制调用者在使用前必须处理其“存在与否”的状态。作者具体展示了如何使用Optional.absent()、Optional.of()等方法创建对象,并演示了其链式调用如何轻松实现“若为空,则使用默认值”的逻辑,例如`person.or(manager).doSomething()`。 与需要为每个类定制的“空对象模式”相比,来自Guava库的Optional方案更为通用和轻量。虽然代码行数没有减少,但它将“是否为空”的判断从隐式的编程习惯,提升为了显式的、由类型系统保障的编码规范,从而在根源上提升了代码的健壮性。
基于Solr的空间搜索(2)
这篇讲的是Solr+Lucene实现空间搜索中GeoHash方案的源码级剖析。作者从索引构建和查询解析两个阶段切入,展示了如何将经纬度转换为Base32的GeoHash编码存入索引,以及查询时如何通过`SpatialFilterQParser`解析用户的距离查询语法。 核心聚焦在查询阶段的实现链条:从`GeoHashField.createSpatialQuery`生成查询,到`ValueSourceRangeFilter`和`GeohashHaversineFunction`协作过滤文档。作者特别指出了流程中一个可能影响性能的环节——过滤逻辑会遍历索引中的所有文档(从docId=0开始),逐一计算每个文档坐标与查询点的球面距离,并判断是否在指定范围内。源码中也有“TODO: optimize this”的标注,表明作者对这种全量遍历加计算的效率有所疑虑。 整体来看,文章像一次带读者拆解黑盒的代码导读,不仅说明了“怎么做”,也提出了对当前实现效率的思考,为理解Solr空间查询的内部机制提供了扎实的细节。
linux内核研究笔记(一)内存管理 – page介绍
这篇讲的是 Linux 内核内存管理中最基础的数据结构——`struct page`。作者以一名服务器程序员的视角,从对“虚拟内存”的好奇出发,深入内核底层,剖析了物理内存管理的核心。 文章首先展示了 `page` 结构体的关键字段,并指出它是内核描述物理内存页的最小单元。核心在于,这片物理页在不同场景下被赋予不同角色:作为页缓存(`mapping` 域)加速文件IO,作为私有数据(`private` 域)用于缓冲或交换,或作为页表映射支撑用户空间的 `malloc`。 作者进一步通过宏定义,解释了页帧号(pfn)与 `page` 指针、物理地址、内核逻辑地址之间的转换机制。比如 `pfn_to_page` 本质上是操作全局数组 `mem_map`,巧妙地将连续的物理内存抽象为可索引的对象。文章还厘清了“内核逻辑地址”与“内核虚拟地址”的区别,并点明在 x86_32 架构下 `PAGE_OFFSET` 的由来。 理解 `page` 结构是窥探内核如何管理伙伴系统、slab分配器乃至整个虚拟内存系统的钥匙。这篇笔记从最底层的数据结构切入,为后续理解更复杂的内存管理机制打下了坚实基础。
雅虎中国:终身免费邮箱
2007年,雅虎中国高调推出“终身免费邮箱”,并扬言要与网易打持久战。然而仅六年后,这项“终身”服务便宣告关闭。 这篇文章复盘了这起商业承诺的演变。作者指出,邮箱本身很难直接盈利,其对互联网巨头的真正价值在于构建一个核心“用户体系”,并以此推行“通行证策略”——用一个账号打通所有服务,从而深度了解用户行为,为商业决策提供支撑,例如谷歌的Gmail与微软的Hotmail。 对于运营雅虎中国的阿里而言,这套逻辑并不适用。阿里自身拥有庞大的电商用户体系和独立的IM工具(阿里旺旺),并不依赖雅虎邮箱来建立通行证。从独立业务看,雅虎中国邮箱也并非市场领导者。因此,在阿里逐步摆脱对雅虎总部的依赖后,关闭这个既不赚钱又缺乏战略意义的业务,便成了顺理成章的选择。文章揭示了一个朴素的商业逻辑:巨头的承诺往往服务于特定阶段的战略,当战略本身发生变化时,“大话”也就有了合理的注脚。
谈谈Facebook的聊天系统架构
这篇讲的是Facebook在2009年公开的聊天系统核心架构。作者从一份内部PDF中的架构图出发,清晰地拆解了支撑数亿用户实时聊天的四个关键模块及其设计考量。 整个系统分为Web Tier(用PHP处理业务逻辑)、Chatlogger(C++开发的消息存储层)、Presence(C++编写的在线状态服务)以及Channel Cluster(基于Erlang和Mochiweb开发的服务器推送通道)。作者着重分析了每个模块的选型逻辑:Chatlogger需要应对海量历史数据,因此依赖Cassandra/HBase;Presence将用户在线状态全部存于内存以追求极致性能;Channel Cluster则通过保持长连接和本地缓存在线列表,实现了高效的实时推送,并减轻了Presence的压力。 文章不仅解释了“是什么”,还点明了“为什么”——例如为什么Presence不用PHP+Redis,为什么Comet服务器需要做二次开发。作者最后总结道,这个架构设计本身已经非常清晰透彻,但在实际应用中,仅靠整合现有开源组件远远不够,必须根据自身技术栈进行深度定制和二次开发,才能应对真正的规模化挑战。
天猫导航的内部机制揭秘
这篇讲的是天猫搜索结果页上方那个看似简单的导航栏,其背后的智能推荐机制。 文章从一个常见场景切入:当用户搜索意图不明确时,导航区的类目和属性推荐就成了帮助他们找到商品的关键。作者务达揭示,这些导航项并非静态存储,而是通过算法动态生成和排序的。 具体来说,导航分为类目导航和属性导航,其推荐逻辑依赖于离线生成的词表。核心算法基于每个(Query,搜索类目)对的点击、成交和商品数数据,进行线性加权排序,决定展现哪些类目/属性以及它们的排列顺序。例如,属性推荐就细分为根类目、公共类目和叶子类目下的属性,当某个属性分数占比极高时,会直接进行“属性预选”展示。 整套系统每天承载着约3000万PV的展现量,是天猫搜索导购链路中的重要一环。文章将智能导航的架构、排序算法以及具体的展现逻辑梳理得清晰透彻,揭开了这个常见却容易被忽视的功能背后的技术面纱。
Java环境变量设置
这篇讲的是Java开发环境搭建的基础操作,作者从配置环境变量到运行第一个程序,演示了一个完整的入门流程。 文章核心是手把手教新手设置JAVA_HOME、PATH和CLASSPATH这三个关键变量,步骤拆解得很细,包括从系统属性入口到具体变量值的填写都有截图说明。特别贴心的是,作者预判了初学者可能卡壳的地方,比如强调命令行切换目录的正确方式,以及源文件命名必须与类名严格一致。 之后用经典的HelloWorld例子串联起来,展示了编译和运行的全过程,让抽象的环境配置变得可感知。最后还简单解释了这三个变量各自的作用,帮助读者不仅知道“怎么做”,也理解“为什么”。整体节奏清晰,非常适合刚接触Java的朋友跟着操作。
从概念的角度审视一淘商品搜索的Online系统架构
这篇技术文章从概念角度剖析了一淘商品搜索系统中的信息组织架构,直指当前设计的不足与优化方向。作者指出,随着商品数量增长,类目、产品节点(SPU/SKU)等层级信息在现有系统中存在割裂,特别是产品节点的类目关系和父子层级在Online系统中未被有效利用,导致搜索结果页(SRP)展示和导航逻辑存在缺陷。 文章引入了两个核心概念:AP(访问点/聚合点)与TAG(属性)。AP用于路径导航(如类目、SPU),TAG用于结果筛选(如颜色、尺寸),两者可动态转化。作者认为,当前依赖离线统计的QP决策机制存在局限,而通过构建并利用一棵完整的“AP树”,系统可以进行实时在线统计,从而更智能地决定产品的展示层次、结构化组合(Combo)以及跳转逻辑,大幅降低人工干预成本,提升用户导航体验。 其核心方案是统一CatId、SpuId、SkuId的数值空间,构建更完整的层级树,并增强模块的数据更新能力。这一架构不仅旨在解决当前节点展现别扭、导航路径单一的问题,还为关联推荐、公共信息提取等更丰富的产品功能打开了空间。
Java包的静态导入import static和import的区别
作者从Java 5引入的静态导入特性出发,详细对比了普通的`import`与`import static`在语法和使用上的区别。普通导入让我们能直接使用类名调用其静态成员,而静态导入则能进一步省去类名前缀,使得代码书写更简洁。 文章通过`System.out.println()`和`Integer.MAX_VALUE`等具体例子展示了这一点。使用静态导入后,冗长的`System.out.println(…)`可以简化为`out.println(…)`,`Integer.toHexString(42)`则变为`toHexString(42)`。这在需要频繁调用同一类静态方法或常量时,确实能提升编码的简洁度。 不过,作者也提醒了它的适用场景和注意事项。静态导入更适合存在大量重复调用的代码段,若仅有零星使用,直接写全称反而更清晰。同时,需要警惕命名模糊问题,例如同时静态导入`Integer`和`Long`后直接使用`MAX_VALUE`会导致编译器错误,因为它无法判断你指的是哪一个。 总的来说,这篇文章讲清楚了如何在代码简洁与可读性之间找到平衡点,帮助开发者更有效地运用这一语法糖。