从LongAdder看更高效的无锁实现
这篇讲的是作者从阅读Guava源码时接触到AtomicLong出发,为何要深入研究Doug Lea设计的LongAdder。文章的核心在于解析LongAdder如何实现比AtomicLong更高并发性能的无锁计数。 我们知道,AtomicLong的高效依赖CAS操作,但在高并发下,大量线程竞争同一个value变量会导致频繁的CAS失败与重试,形成恶性循环。LongAdder的核心实现思路正是解决这个问题:它采用“分段更新”的策略,将单一value的压力分散到一个Cell数组中。 具体来说,当CAS更新base值失败时,LongAdder会根据线程信息将更新操作分散到cells数组的某个Cell单元上。每个线程尽可能只更新自己命中的那个Cell的value值,从而极大降低了高并发下的冲突概率。只有当需要获取总数时,才将base值与所有Cell的value累加。文章还巧妙地分析了其中的权衡:在低并发时,CAS更新base值大概率成功,不会立即进入分段逻辑,从而兼顾了空间与效率。此外,当分段更新本身也失败时,`retryUpdate`方法会进行cells数组的扩容和重哈希,进一步降低冲突。 作者通过逐行解析`add`方法和`retryUpdate`逻辑,清晰地揭示了这种以空间换时间、通过降低热点数据“热度”来换取吞吐量提升的精妙设计。这正是一篇典型的源码分析文章,带我们看到了高并发场景下无锁算法的一个经典优化范例。
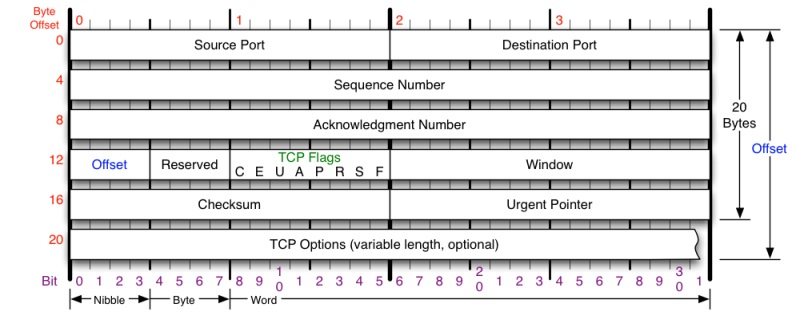
TCP 的那些事儿(上)
这篇讲的是TCP协议的核心机制,作者从一个经典却复杂的网络协议出发,试图用清晰的方式梳理其设计原理。文章开篇就点明了学习TCP的挑战,并直接切入重点:TCP头格式。它解释了序号、确认号、窗口和标志位这四个关键字段如何分别解决网络包乱序、丢包、流控和状态控制这些实际问题。 接着,文章用两张图——TCP状态机与建连/断连流程——对照着讲解,把三次握手为何必要、四次挥手的本质说透了。它特别分析了ISN序列号初始化如何避免旧包干扰,以及TIME_WAIT状态存在的双重意义。更有价值的是,作者深入到了实战细节:比如Linux下SYN超时的重试策略(默认63秒),并警示了SYN Flood攻击的原理与tcp_syncookies的应对方式及其局限性。 这不是一篇面面俱到的协议手册,而是聚焦于TCP最根本的“连接”幻觉与可靠传输的实现,通过状态机和具体参数(如MSL、tcp_max_syn_backlog)的剖析,展现了这个30多年协议在精巧设计与现实妥协之间的平衡。读下来,能对那些看似理所当然的网络行为,建立起更扎实的认知。
互联网思维的企业,互联的企业
作者读完《互联网思维的企业》后,陷入了长考。他从自己早年的观察出发,指出“互联”才是沟通方式碎片化与身份实名化背后的真正趋势。这本书让他意识到,简单的技术应用只是表象,企业必须从根本上重构组织模式来应对这个新时代。 文章以客服部门为例,深刻剖析了传统“机械思维”的弊端:为效率设计的封闭流程,在社交网络时代反而可能放大负面口碑。书中提出,互联时代的企业应像有机生态一样生长——打破刚性部门墙,以开放平台取代严密控制,让团队在共同目标下自发协作、解决复杂问题。这需要领导者建立基于目标、立场与原则的“道德感召力”,而非事必躬亲。 作者认同这种“磁场”般的领导哲学,但也冷静指出,实现自组织需要员工具备高度的自驱力,这对人才提出了前所未有的要求。这篇文章最终引导我们思考:在追求互联与开放的同时,如何培育能适应这种土壤的个体?
php内核探索之zend_execute的具体执行过程
这篇文章从底层源码出发,剖析了PHP脚本引擎执行PHP代码的核心路径。它聚焦于引擎初始化的默认执行函数`execute`,并对其完整执行流程进行了逐行解读。 核心实现思路清晰展现:`zend_execute`本质上是个函数指针,指向`execute`函数。该函数首先为`zend_execute_data`分配并初始化执行上下文,包括CV变量表、临时变量空间以及保存当前执行状态,这类似于进程调度时的上下文保存。随后,进入一个无限循环,通过调用当前op指令的handler来驱动每一步操作,并根据handler的返回值(如跳转、函数调用)来控制流程。 文章的巧妙之处在于揭示了PHP虚拟机动态分派的关键机制。它详细解释了传入的`zend_op_array`结构体,特别是其`type`字段如何区分全局代码、用户函数和eval代码,明确了这些不同的代码块在执行层面本质上都是同一种操作数数组。最终,所有复杂的PHP逻辑都归结为对opcodes数组中每条指令handler的循环调用。 整篇文章用代码级的追踪,清晰展示了从`zend_execute`入口到单个操作码handler被调用的完整链路,是理解PHP运行时底层运作的扎实资料。
vfork 挂掉的一个问题
这篇讲的是 vfork 系统调用中一个经典的“坑”:为什么在子进程中使用 `return` 会导致程序崩溃,而用 `exit()` 却不会?作者从知乎上的一个实际提问出发,澄清了一些可能误导人的回答。 文章首先梳理了 fork 与 vfork 的根本区别——fork 会复制父进程内存,而 vfork 则让父子进程共享同一内存空间。vfork 的设计初衷是为了在创建子进程后立即执行 exec 时提高效率。关键点在于,vfork 保证子进程先运行,直到它调用 `exit()` 或 `exec()` 后,父进程才继续。 崩溃的根源正在于此:因为父子进程共享栈空间,如果在子进程的 main 函数中使用 `return`,它会像正常函数返回一样修改栈(弹栈、释放局部变量),这相当于破坏了父进程正在使用的栈。当父进程稍后恢复执行时,栈已被改写,导致不可预知的行为或直接崩溃。而 `exit()` 是直接终止进程,不会去操作和释放共享的函数栈,因此父进程能安全恢复。 文章最后也指出,现代操作系统已通过“写时拷贝”技术大幅优化了 fork,使得 vfork 的性能优势不再明显,Linux 手册也不鼓励使用它,除非对性能有极致要求。理解这个底层机制,有助于我们避免这类隐蔽的陷阱。
State Threads 回调终结者
这篇讲的是如何用 State Threads (ST) 这个仅3000行C代码的轻量级库,来终结高性能服务器开发中令人头疼的异步回调噩梦。作者从此前介绍的协程库 Protothreads 出发,引出了这个更适合服务器领域的“宝藏”项目。 文章的核心在于将 ST 与传统的事件驱动状态机(EDSM)进行对比。传统 EDSM 依赖异步回调,开发者需要将线性的处理逻辑拆解成一堆回调函数,心智负担沉重。而 ST 的巧妙之处在于,它在 EDSM 的内核之上,为每个网络连接抽象出一个“线程”概念。这个线程并非操作系统线程,而是由 ST 自己在用户空间调度的轻量级执行体。 ST 的调度器通过模拟 setjmp/longjmp 来切换这些“线程”的上下文,整个过程没有系统调用开销。只有当所有“线程”都在等待 I/O 时,才会触发一次真正的 select()/poll() 系统调用。这样,开发者可以用接近写多线程同步代码的直观方式(线性思维)来编写高性能网络程序,同时又享受事件驱动模型带来的低开销与高可扩展性,避免了回调割裂逻辑的复杂性。 文章还梳理了 ST 从网景、SGI 到 Yahoo! 的发展历史,并讨论了其 MPL/GPL 双许可证的兼容性细节。尽管这个库已稳定多年未再更新,但其“结合多线程编程简洁性与事件驱动性能”的设计思想,至今仍对理解服务器编程模型有重要启发。
一次php进程诡异退出的排查过程
这篇文章讲述的是一个常驻PHP进程总在莫名退出时,如何一步步定位到信号干扰并解决的实战经验。 作者在反垃圾平台的离线扫描部分遇到了一个“诡异”问题:一个用`while(1)`循环的PHP守护进程会不定期退出。最初怀疑是致命错误,但通过`register_shutdown_function`捕获后发现,该函数在进程退出时根本没有执行,日志一片空白。这提示退出可能并非源于PHP内部错误。 根据官方文档注释,作者意识到当进程收到SIGTERM或SIGKILL等信号时,`register_shutdown_function`会被跳过。于是,他转而使用`pcntl_signal`为一系列常见信号(如SIGTERM, SIGHUP等)安装自定义处理函数,以记录是哪个信号导致了退出。 最终,日志锁定了元凶——SIGALRM(alarm信号)。这只是一个无关紧要的定时器信号,但默认行为就是终止进程。解决方案很直接:在信号处理函数中,对SIGALRM进行特殊处理,直接忽略它,而对其他信号则记录后干净退出。 这个案例展示了在Linux环境下排查PHP进程异常退出的典型思路:当高级的错误捕获机制失效时,问题根源很可能在更底层的操作系统信号层面。通过合理捕获并处理这些信号,就能有效“驯服”那些看似毫无征兆的进程退出问题。
妙用php中的register_shutdown_function和fastcgi_finish_request
这篇讲的是 PHP 中两个常被混淆的“请求结束期”函数:`register_shutdown_function` 和 `fastcgi_finish_request`。虽然它们都在脚本执行尾声触发,但一个负责“善后”,一个用于“提前下班”。 `register_shutdown_function` 注册的函数,即使遇到 fatal error 或主动调用 `die()` 也会执行。文章展示了它的两个实用场景:一是作为“黑匣子”记录错误现场,比如精准捕获内存溢出的详细信息;二是用于监控请求是否异常中断,确保关键流程可追溯。 `fastcgi_finish_request` 则完全不同,它是一个“分水岭”。调用之后,所有输出都会发送给客户端,之后的代码(如日志记录、数据清理)虽然继续执行,但不再产生网页输出。文章用代码演示了如何用它来优化响应速度——把用户不需要看到的耗时操作,挪到“已响应”之后进行。 文章通过具体的代码示例和输出对比,清晰地区分了两者:一个保障程序的健壮性与可观测性,另一个则专注于提升前端的响应体验。
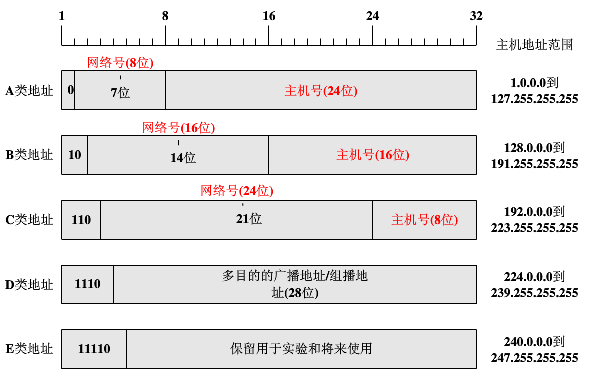
ip地址中的网络号,主机号
这篇文章讲的是IP地址的核心结构——网络号与主机号。作者开篇就用了一个很形象的比喻:如果说MAC地址是你唯一的身份证号,那IP地址就是你详细的通信地址。这个地址被分成两部分:“网络号”标识你所在的网络(好比哪个城市或街道),而“主机号”则标识该网络上的具体设备(好比门牌号)。这种层次化的设计,让互联网上的通信定位变得高效有序。 文章的重点在于“如何计算”。作者以一个具体的IP地址(192.9.200.13)和子网掩码(255.255.255.0)为例,手把手演示了计算过程:先将两者转换为32位二进制,然后通过“按位与”运算得出网络号(192.9.200.0),再将掩码取反后与IP地址“按位与”得到主机号(13)。整个过程清晰展示了子网掩码的核心作用——就像一把尺子,精准地划分出IP地址中网络与主机的边界。 此外,文章还补充了IP地址的五类分类法(A、B、C、D、E类)及其二进制特征,并解释了子网掩码的另一种简洁写法(如/24代表前24位为1)。这些知识点串联起来,能帮助读者不仅知道“是什么”,更理解“怎么算”以及“为什么这么设计”,是理解网络通信基础的一个扎实入门。
怎样获取PHP函数默认参数常量名
这篇讲的是PHP中如何获取函数默认参数的常量名称。作者从实际编码场景切入,当函数定义中使用常量作为默认参数时,开发者可能需要在运行时获取这个常量名,但早期版本的PHP对此无能为力。 关键对比在于PHP版本差异:在PHP 5.4.6之前,函数定义属于编译时信息,运行时反射API无法直接访问常量默认参数名。文章指出,直到PHP 5.4.6才通过反射扩展
PHP中的NOP及为什么有这个opcode
这篇讲的是PHP虚拟机(Zend VM)中一个看似“无用”的指令:ZEND_NOP。作者从汇编语言中的空操作指令切入,解释了PHP作为高级语言为何还需要它——这源于编译器的优化策略,而非底层内存对齐的考虑。 文章核心展示了PHP的“早期绑定”机制。在编译阶段,如果函数声明或类声明(如代码中的Bar类)能被确定,其对应的执行指令就会被直接替换为ZEND_NOP。通过VLD调试工具的输出对比,读者能清晰看到,处于条件语句内、编译时无法确定的Foo类仍需DECLARE_CLASS指令,而Bar类的声明已被优化掉。 作者进一步探讨了为何不移除这些NOP指令。关键在于opcode数组的内存是预先按文件分配的,移除单个NOP并不能回收空间。对于Zend引擎而言,类和函数声明的数量相对于总指令数很少,为此修改引擎结构的收益有限。而像eAccelerator这类opcode缓存扩展,则会在编译优化阶段主动移除NOP以提升后续执行效率。 整篇文章从一个具体指令出发,揭示了PHP编译优化与执行模型间的协作细节,帮助开发者理解那些“静默”发生的性能考量。
从未降级的搜索技术-Hippo在线服务调度系统
这篇讲的是,在搜索团队经历了一次手忙脚乱的双11“搬机器”救援后,如何从零开始构建一个真正服务于在线系统的调度平台——Hippo。 故事要从一次教训说起。当年双11,团队为天猫和主搜分别预留了14倍和1倍的资源余量。然而流量突变,主搜压力远超预期,天猫却只涨了4倍。工程师们被迫手动迁移机器来救场,改配置、发数据、起进程,折腾一个半小时才勉强应对。更无奈的是,这种紧急操作往往还未必能准确命中流量高峰。每年大促都像一场无法预演的战役,让运维和开发都身心俱疲。 为了解决这些痛点——资源僵化、扩容迟缓、手动部署风险高,团队调研了当时主流的调度系统。但发现Yarn对于C++在线服务显得笨重,而FUXI和Mesos在资源回收上采用强制策略,可能影响在线服务的稳定性,这与搜索系统“高可用、资源分配稳定”的核心要求相悖。因此,他们决定自研一个专注在线服务的平台。 Hippo采用了两层架构:Master层负责核心的资源管理与调度,而具体的AM层则允许各应用定制自己的调度逻辑。它的设计核心在于保证在线服务的平稳运行:资源回收策略更为柔性,并针对海量数据(如40G索引、多GB模型)的快速分发和部署做了特别优化。这篇文章详细拆解了系统从需求诞生到架构落地的全过程,展示了一个为复杂在线场景量身定制的调度系统是如何思考的。
聊聊多线程程序的load balance
这篇讲的是,如何在一个常见的“接收者-工作线程池”模型中,主动优化负载均衡以提升性能。作者从一个大家熟悉的设计出发:一个 receiver 线程接收请求,放入队列,通过条件变量唤醒任意一个 worker 处理。他敏锐地指出,完全依赖内核的调度和负载均衡可能带来问题。 核心问题有两个:如果 worker 线程远多于 CPU 核心数,唤醒时几乎无法均匀分配到不同 CPU,导致某些核过载而某些核空闲,形成“伪并发”。其次,即使 worker 数量合理,内核的负载均衡也未必能确保将任务分配到不同的物理核心(避免争抢共享缓存和计算资源)。 对此,作者提出了应用层的“微调”方案。一方面,将 worker 线程数控制在接近或略小于 CPU 核心数。另一方面,更关键的是,通过线程绑定(affinity)固定 worker 在特定 CPU 上,并设计一个分级的条件变量唤醒机制。这能确保新任务被优先分配给空闲或低负载物理核心上的 worker,从而主动实现更优的负载分布。 文章通过精心设计的实验验证了结论。例如,将 worker 线程数从 240 降至 24 后,CPU 利用率从 2200% 提升至接近 2400%。启用绑定线程和分级唤醒后,处理 12 个并发任务时性能得到进一步提升。作者也发现,对于依赖内存缓存的任务(如 mmap 读文件),让 worker 集中在相邻 CPU 上反而可能提升性能,这体现了负载均衡策略需具体场景具体分析。 作者通过细致的对比实验表明,这些在应用层主动进行的微调,有时能取得比等待内核调度更优的效果。
从未降级的搜索技术-天猫SKU搜索
这篇技术文章详细拆解了天猫搜索从“商品级”跨越到“SKU级”的完整演进历程。作者直面传统搜索的痛点:当用户想买特定规格(如64G白色iphone6)时,旧引擎只能按商品维度返回结果,导致价格展示不准确、过滤和排序形同虚设。 文章核心聚焦于如何实现既能支持SKU粒度精准检索,又不造成海量数据冗余的难题。最终提出的“主表(商品)+子表(SKU)”二维架构是解决方案的关键:引擎能同时处理两个维度的查询,并形成“一主带多子”的结果结构,让过滤、排序等环节都能基于真实的SKU信息工作。 通过CSPU聚合、精准排序等具体场景的实现,该技术上线后在多个类目带来了可度量的收益,例如沙发类目平均IPvUV价值增长8.50%。这不仅是一次架构升级,更是将“尺码个性化”等精细体验从想法变为现实的基石。
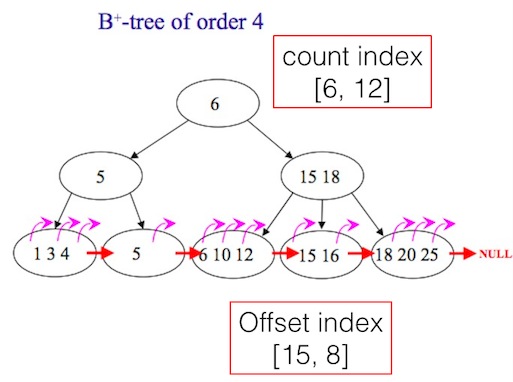
为什么超长列表数据的翻页技术实现复杂(二)
这篇讲的是如何为超长列表设计高效的翻页方案。作者延续上篇对问题的探讨,以新浪评论系统的经典演进为引子,剖析了从缓存翻页到自定义文件索引等方案的演进与局限,最终聚焦于一个核心矛盾:MySQL常用的B-TREE索引结构,虽擅长点查,却天生不利于范围查询(Range Scan),导致翻页性能低下。 为此,文章提出了两种实用的二级索引思路。一是“Count index”,通过额外记录每个非叶子节点下的条目总数,实现对任意offset位置的快速定位。二是“Offset index”,在应用层(如Redis)缓存部分offset与对应ID的映射关系,当需要定位某个offset时,可以从最近的缓存点开始扫描。 文章进一步给出了这两种思路在MySQL和Redis中的具体实现示例。比如Count index可以建一张辅助表按月份记录各用户的评论计数,而Offset index则在用户翻页时动态缓存到Redis,并在数据变更时及时清理。这两种方法都已在实际生产环境中得到验证,为解决超长列表的翻页难题提供了清晰且可落地的技术路径。
第三方支付为什么会兴起
这篇文章从作者多年的外贸经验切入,探讨了一个有趣现象:为何在国际贸易中早已成熟的银行担保模式(如信用证),到了国内电子商务领域,却被第三方支付全面取代。 作者指出,支付宝的担保交易原理与信用证如出一辙,都是为了解决远程交易中的信任问题。但奇怪的是,银行并未将这套成功的经验复制到国内网购市场,这种“不闻不问”的态度,为第三方支付的崛起留下了巨大的市场空白。文章还对比了信用卡的历史——它同样由第三方机构首创,后因银行受地域经营限制,才催生出跨行合作的卡组织来反超。 核心观点在于,银行因过往业务过于舒适,低估了互联网支付的战略意义,未能及时行动。等到第三方支付从工具演化到金融平台时,格局已定。文章最后抛出一个开放性问题:历史上第三方支付曾颠覆信用卡旧模式,未来它是否会进一步侵蚀银行信用证业务?这不仅是商业策略的复盘,也揭示了技术浪潮中,巨头的疏忽如何让机遇溜走。
为什么 skynet 提供的包协议只用 2 个字节表示包长度
这篇讲的是 skynet 框架中一个经典设计决策:为什么它的 netpack 库坚持使用 2 字节(最大 64KB)来表示 TCP 数据包长度,而不是更“灵活”的 4 字节。 作者从游戏客户端网络通信的实际场景出发,解释了这并非简单的技术限制,而是一种有意的引导。核心原因在于,在单个 TCP 连接中允许过大的数据包(比如 100KB)是一个糟糕的设计。这会在弱网环境下长时间阻塞整个通信信道,连带心跳包等需要及时响应的小数据包也被延迟,严重影响实时性。更进一步,4 字节的长度头还存在被恶意攻击耗尽服务器内存的安全风险。 因此,作者主张正确的做法不是放宽包长度限制,而是在“长度+内容”协议之上增加一层,将大数据块分片传输。这个设计看似“绕”,但它强制开发者去思考和解决数据传输的阻塞问题,最终能实现单个 TCP 连接承载多个逻辑信道的能力,比如区分高优先级的心跳/关键指令和低优先级的聊天信息或大文件分片。 所以,skynet 这个看似限制性的选择,其实是在用简洁的接口引导使用者构建更健壮、响应更及时的网络架构。
操作系统-进程管理
这篇系统梳理了操作系统进程管理的核心概念。作者从最基础的定义切入,指出进程是程序的一次动态执行过程,并详细对比了它与静态程序在存在形式、生命周期、资源分配角色上的五大关键差异。 文章接着拆解了进程的内部构成,重点呈现了进程状态的演进——从经典的三种状态模型,到更贴近实际的五种、七种状态切换图,这直观反映了现代操作系统对进程调度的精细化控制。在调度层面,文章清晰列举了先到先服务、优先级、最短作业优先、循环轮转以及多级队列这五种经典算法,为理解CPU资源如何公平高效地分配给不同进程提供了具体思路。 此外,文章也涵盖了进程间通信的七种主要方式(如管道、共享内存、套接字等),并最终引向了更轻量的执行单元——线程,明确了进程与线程在资源分配与调度层面的分工关系。整篇内容结构清晰,从定义到组件,再到调度与通信,最后延伸到线程,为构建操作系统进程管理的完整知识图谱提供了扎实的路线。
Linux程序链接时-lpthread对程序正确性的影响
作者线上服务频繁卡死,CPU使用率飙升。通过pstack堆栈分析,发现线程大量阻塞在pthread_cond_signal和mutex解锁操作上,但本应轻量的unlock函数却异常消耗资源。排查指向了链接时未指定-lpthread的隐患。 文章深入剖析了这一常见陷阱背后的机制。在glibc中,pthread相关函数(如mutex、条件变量)存在“空实现”以优化单线程程序性能。只有当程序显式链接libpthread.so后,其正确的多线程实现才会覆盖libc中的符号。作者通过readelf和nm工具对比发现,动态库通过versioned symbol(如pthread_cond_signal@GLIBC_2.3.2)实现这一覆盖,而非静态库使用的weak symbol。 关键在于,若主程序或最终可执行文件未链接pthread库,即使动态库本身依赖多线程,程序启动时加载的仍是libc中的空实现,导致死锁等严重问题。作者通过复现实验证明,只要最终可执行文件链接了-pthread,即便中间动态库未链接,也能通过符号版本机制正确解析到pthread库的实现,从而规避风险。
nginx中location的匹配和rewrite
这篇文章来自一位工程师的实战经历,他在调整线上 Nginx 规则时,遇到了一个关于 `location` 匹配的“诡异”问题:明明配置了精确的路径规则,流量却匹配不上。 问题的根因在于 Nginx 对待 URL 的两个阶段存在处理差异。用户直接请求的 URL 会先进行“归一化”处理(例如合并多余的斜杠),但在配置文件中使用 `rewrite` 指令跳转后生成的新 URL,却不会再经历这一过程。这种不一致,极易导致配置失误。 文章用一个具体例子清晰演示了这一点:当 `rewrite` 规则不小心多写了一个斜杠,形如 `/newapi//api`,直接访问 `/api`(归一化后)就无法命中 `/newapi/api` 这个 `location`;而直接请求未归一化的 `/newapi//api` 反而可以匹配上。 作者通过这个踩坑经历,揭示了 Nginx 转发机制中一个容易被忽略的细节。对于需要编写复杂规则的运维和后端同学来说,理解这个机制差异,能帮助避免一些难以排查的线上配置故障。