Linux开关机命令详解
这篇技术文章系统梳理了Linux系统中五种常见的开关机命令(shutdown、reboot、poweroff、halt、init),非常适合对服务器日常运维感兴趣的开发者。作者没有停留在简单罗列命令,而是深入比较了它们的参数差异与执行逻辑。例如,shutdown命令功能最为全面,支持定时关机、警告用户以及取消操作;而halt和poweroff则更直接,适合立即断电的场景;init命令通过切换运行级别(0为关机,6为重启)来实现控制。 文章的一个亮点是特别强调了“关机准备”这一实践步骤。它提醒读者,Linux非正常关机可能导致文件系统损坏,因此在执行命令前应使用`who`、`ps`、`netstat`检查系统状态,用`sync`同步磁盘数据,并通过`shutdown -k`提前通知在线用户。这些细节对于保证生产环境稳定性至关重要。此外,文中还列举了通过SSH远程执行重启命令的用法,体现了实际运维中的常见需求。 整体而言,这不仅是一份命令参考手册,更传达了安全、规范的操作理念。对于需要频繁管理Linux服务器的工程师,文中关于参数选择和操作流程的对比分析,能帮助他们在不同场景下做出最合适的选择。
51CTO专访腾讯高级运维工程师刘天斯
这篇腾讯高级运维工程师刘天斯的专访,分享了他从天涯社区到腾讯十年来的实战心得。他一针见血地指出,许多团队盲目推进运维自动化却收效甚微,根本原因在于跳过了“标准化、流程化、规范化”的基石建设。他用一个巧妙的比喻说明:运维工作像散落的珠子,需要用“流程”这根线串起来,并由“标准规范”控制顺序与间隔,最终锚定在质量、效率与成本这三个核心点上。 访谈深入探讨了云计算和大数据时代带来的新挑战。刘天斯强调,面对私有云和容器化(如Docker)的兴起,运维人员不仅要会用云,更要精通资源调度、监控与自动化工具,以实现业务的快速弹性伸缩。而在大数据场景下,运维更需掌握Hadoop、Spark等技术栈,通过实时计算过滤告警、离线分析数据,从而真正“懂业务”。 对于未来,他认为自动化运维的终极目标——如一键上线、故障自愈——仍是行业共同追寻的理想状态,这需要长期的积累与优化。他特别建议运维工程师必须具备扎实的开发能力,因为“没有人比我们更清楚需要什么样的平台或工具”,这将赋予你在协作中更多的主导权。
开发者的黄金时代=运维人员的恶梦?
这篇文章从DevOps盛行的背景出发,探讨了软件开发环境巨变下开发与运维角色面临的不同境遇。 作者指出,过去十年,开源和云服务的兴起彻底改变了开发者的工具箱。他们不再受限于昂贵、整合慢的传统大型软件,而是可以根据需求自由选择免费、灵活的各类工具(如Redis、Elasticsearch等),实现了更快的集成与持续部署,产品迭代效率大幅提升,这正是“开发者的黄金时代”。 然而,工具的丰富与分工也为运维带来了“恶梦”。变更速度的加快意味着监控与响应需求激增;而由大量独立工具构成的现代基础设施,使得可移动部分增多、依赖关系复杂,导致“报警疲劳”。数据显示,运维人员多达50%—70%的时间可能被消耗在应对各类警报上,影响了其构建核心基础设施的工作。 文章最终落脚于,这种矛盾正推动DevOps模式的深化。它强调打破开发与运维的壁垒,通过建立共同的关系、流程与工具来协作应对挑战,从而更高效地创造商业价值。
Linux下使用rsync进行数据备份的命令详解
这篇讲的是运维中不可或缺的rsync数据备份工具。文章从rsync的核心优势切入——它通过只传输变化部分来节省带宽,利用SSH加密保障安全,并支持压缩传输。 作者没有停留在理论,而是直接通过六个具体命令示例,手把手展示了rsync的灵活应用。从最基础的本地目录同步与压缩选项(-zvr),到用“-a”参数保留所有文件属性,再扩展到跨机器的双向同步:既可将本地文件推送到远程服务器,也能将远程数据拉回本地。 文章还特别演示了如何用rsync比对源与目标间的文件差异,这对于确认同步状态非常实用。最后,示例展示了如何将rsync命令写入cron任务,实现自动化的定时备份。 整篇文章就像一份实战指南,把rsync从简单的复制工具提升到了可靠、高效的数据同步与备份方案,非常适合需要快速掌握rsync实际用法的运维人员参考。
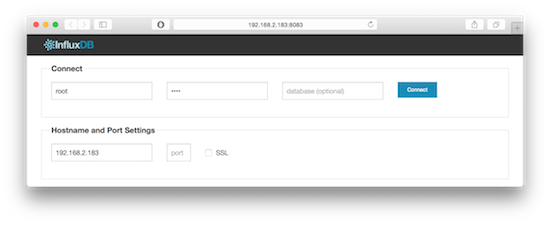
使用 Grafana+collectd+InfluxDB 打造现代监控系统
这篇技术文章介绍了一套完整的监控系统搭建方案,目标是使用开源工具组合出类似New Relic的实时可视化监控效果。其核心架构思路是让数据流依次经过采集、存储、展示三个环节,分别由collectd、InfluxDB和Grafana这三个各司其职的组件完成。 文章详细阐述了三者的分工与集成:collectd作为轻量级性能采集工具负责收集各类系统指标;InfluxDB作为专为指标数据设计的时序数据库,负责高效存储这些数据;最后,Grafana这个前端可视化工具连接InfluxDB,将数据转化为直观的仪表盘和图表。文章并没有停留在概念层面,而是给出了在Ubuntu系统上从零开始的具体部署指南。它逐步演示了如何安装配置InfluxDB,创建数据库,并启用其内置的collectd插件来直接接收数据流,省去了以往需要第三方代理的麻烦。同时,也清晰地说明了collectd客户端如何配置以将数据发送到指定服务器,以及Grafana如何连接数据源并启动。 通过这套方案,运维或开发团队可以摆脱昂贵的商业监控软件,利用成熟开源组件快速搭建起一套功能完备、数据实时刷新的监控平台,实现对服务器性能的深入洞察与管理。
Linux shell脚本使用while循环执行ssh的注意事项
当用while循环结合ssh批量处理服务器时,很多人会遇到脚本在首个任务后意外终止的诡异问题。这篇文章就针对这个经典“坑”,做了一次透彻的拆解。 问题现象很明确:一个用于批量获取服务器运行时间的脚本,在循环中调用ssh命令后,只处理了第一个IP就退出了。作者分析了根因——while循环通过重定向读取IP列表文件,但ssh命令会“吃掉”这个输入缓冲区,导致循环体内部的read命令无数据可读,循环因此提前结束。 解决这个坑提供了两种清晰的思路。一种是“换条路走”,直接将while循环改为for循环,因为for循环是逐词解析命令输出,不会预加载整个文件,从而避免了输入流被ssh截获。另一种是“原路修复”,在ssh命令后加上-n参数,该参数会明确禁止ssh从标准输入读取数据(等同于将输入重定向到/dev/null),从而“归还”了被占用的输入流,让while循环能正常推进。文章给出了具体的代码示例,是一个非常实用的填坑指南。
运维不得不知的 Linux 性能监控、测试、优化工具
系统性能专家 Brendan Gregg 在 LinuxCon NA 2014 大会上,更新了他关于 Linux 性能分析的经典演讲。这篇介绍正是基于他分享的最新内容,旨在为运维人员梳理一套实用工具集。 面对纷繁的 Linux 性能工具,Brendan Gregg 提出了一个朴素的观点:最好用的往往是那些久经考验、简单直接的小工具。文章的核心内容,就是三张清晰分类的工具全景图,分别对应性能工作的三个关键环节:监控、测试与优化。 具体来说,文章通过三张图表系统性地覆盖了 Linux 各个子系统(如 CPU、内存、磁盘 I/O、网络)在不同场景下可选用的工具。第一张图聚焦于系统可观测性,列举了用于实时监控和诊断问题的工具;第二张图总结了进行性能基准测试与评估的工具;第三张图则归纳了用于系统调优与参数设置的工具。这种结构化的梳理,直接解决了“该用哪个工具”的常见困惑。 这套工具的价值在于其历经实战检验,专注于解决具体问题。对于需要快速定位性能瓶颈或优化系统的运维人员而言,这相当于获得了一份经过专家认证的“工具菜单”,能帮助他们从眼花缭乱的选项中,高效地找到合适的武器。
Linux,du、df统计的硬盘使用情况不一致问题
在Linux服务器上用`du`统计目录大小只有2G,但`df`显示硬盘却已占用3G甚至更多,这种不一致让不少运维同学困惑过。这篇文章就系统地拆解了背后的三大元凶。 首先是ext文件系统预留的“急救空间”。这部分空间`df`会计入已用,但`du`完全感知不到,作者指明了如何用`tune2fs`查看和调整这个数值。 其次是“幻影文件”。当文件被删除但进程句柄未释放时,`du`已经不统计它了,但磁盘块仍被`df`计算在内。文中给出了通过`lsof`查找这类文件并处理进程的方法。 最隐蔽的是第三种情况:在目录挂载新设备前,如果其中已有数据,这些数据会被“隐藏”——`du`和`df`在新设备上都看不见它们,但它们实实在在占用了原设备的空间。文章详细说明了如何安全地卸载、清理这些残留数据。 这篇文章从运维中一个看似小、却容易让人卡住的矛盾点切入,清晰梳理了原理和排障路径。理解了这些机制,下次再遇到`du`和`df`“打架”,你就能快速定位是哪一种情况,并对症处理了。
Nginx带宽控制
这篇讲的是作者如何用Nginx替代Squid来实现文件下载的带宽控制。他首先介绍了Nginx自带的 `limit_rate` 和 `limit_rate_after` 指令,可以轻松设置“下载超过500KB后限速50KB/s”的规则。 但挑战在于,这是单连接限速。如果想控制总带宽(比如总出口100M),单纯限制每个连接速度并不够灵活,无法应对用户数变化带来的动态调整。为此,文章组合使用了 `limit_conn` 模块来限制并发连接数,从而变相控制总带宽,并分析了这种方案的局限性。 文章还探讨了更根本的解决方案:使用第三方 `limit_speed` 模块,或者借助Linux底层强大的TC命令进行流量整形(尽管配置复杂)。结尾处,作者推荐了功能相关但场景不同的 `limit_req` 模块。整体来看,文章从一个实际需求出发,梳理了Nginx在带宽控制方面的多种能力与边界,提供了不同复杂度下的实践思路。
在vim保存时获得sudo权限
这篇讲的是在vim编辑器中,如何不退出进程就能获得sudo权限来保存只读文件。 在维护线上服务的过程中,工程师经常需要编辑那些只有读权限的文件——比如系统配置或日志文件,它们通常属于其他用户。每次保存时,vim都会提示“read-only”,迫使你先退出编辑,再用sudo vim重新打开文件进行保存。这种反复切换的操作不仅繁琐,还容易打断思路,尤其在紧急修复时更显低效。 文章作者从这一常见痛点出发,分享了一个巧妙的解决方案:使用vim命令 `:w !sudo tee %`。这个命令允许在vim内部直接调用sudo权限,将当前缓冲区的内容保存到文件,无需中断编辑进程。具体来说,`:w !{cmd}` 执行外部命令`{cmd}`,并将缓冲区内容通过stdin传入;tee工具负责将stdin保存到文件;而`%`是vim中的一个只读寄存器,始终存储着当前编辑文件的路径。因此,整个操作相当于从vim外部修改了文件,巧妙地绕过了权限限制。 这个技巧能极大提升运维效率,避免反复退出和重启vim的麻烦。它展示了vim命令行的强大灵活性,以及如何利用外部工具增强编辑器的功能——对于经常处理系统文件的技术人员来说,这无疑是一个实用且高效的工作流优化。
监控进程
这篇讲的是Linux下如何更灵活地监控和管理进程。当服务因资源耗尽、程序崩溃或误操作意外终止时,虽然系统自带的SysVinit、Upstart或Systemd能实现基础重启,但应对“CPU占用超标就重启”或“同时管理数百个PHP Worker”这类复杂场景就显得力不从心。 文章随后深入对比了Monit和Supervisor两款专业工具。Monit通过轮询进程状态,能实现基于资源阈值的智能监控与重启,比如配置其在Nginx的CPU使用率连续5次超过80%时自动重启。Supervisor则擅长批量管理同类进程,可以轻松配置并维持100个PHP Worker进程的常驻数量,它更专注于进程的生命周期管理。 不过,两者各有特点。Monit更像一个灵活的资源监控与响应器;Supervisor则是强大的进程组管理器,但通常要求被管理的进程以前台模式运行。文章还巧妙地解决了一个递归问题:如何监控监控者本身?通过让SysVinit来“守护”Supervisor进程,利用系统的初始化能力构建了一道最后的防线。
Linux系统监控工具之vmstat详解
这篇讲的是Linux系统监控工具vmstat的深度使用指南。作者从虚拟内存的运行原理出发,详细拆解了vmstat命令的用法,并重点解读了输出中每一个字段(如进程队列r和b、内存和交换区的si/so、CPU的us/sy/id/wa等)的实际含义与诊断价值。 文章最实用的部分是结合了三个不同负载场景的案例演示。作者特别指出了一个经验细节:vmstat的首次输出往往不准确,需要观察后续结果。通过对比空负载、高CPU使用以及高CPU与高内存使用三种情况下的输出,清晰地展示了如何从数字中发现瓶颈。例如,在高内存压力案例中,swap使用率高达80%、CPU的wait%达到70%,由此推断出是内存不足导致频繁的磁盘交换,最终拖慢了整体性能。 通过升级内存至8G前后的对比数据,文章直观呈现了问题解决后的性能回归正常。整体而言,这篇文章不仅教会读者使用一个工具,更演示了如何通过关键指标进行系统健康度的“体检”与故障推断。
Linux系统的CPU使用率和Load
这篇文章详细拆解了Linux系统中两个核心但常被混淆的性能指标——CPU使用率与系统负载(Load)。作者没有停留在概念定义,而是深入剖析了它们的统计口径与内在关联。 文章指出,CPU使用率直观反映CPU时间片的占用情况(如%user, %system, %iowait等),可通过top、sar等命令查看。而Load则是一个更综合的“压力”度量,它不仅包含正在运行和等待运行的进程(R状态),还包含了处于不可中断睡眠状态(D状态,通常因等待I/O)的任务,这是两者最关键的区别。 作者通过具体场景澄清了常见的困惑:当系统运行CPU密集型程序时,CPU使用率和Load通常会同步升高;但若是I/O密集型任务或内存不足触发Swap,你可能会看到Load值很高,而CPU使用率却并不高。对于“多少Load算高”,作者给出的经验法则是,当Load持续接近或超过CPU核心数时,就值得深入排查。 文章最后推荐了sar -u、sar -q等实用命令组合,并提供了官方手册和延伸阅读资料,帮助读者建立更完整的认知。对于想厘清性能监控基础概念的运维和开发人员,这篇内容提供了清晰、实用的梳理。
CentOS配置vsftpd服务器
这篇文章记录了作者在CentOS上配置vsftpd、搭建允许匿名用户上传下载的FTP服务器时,遇到并解决的三个典型故障。 首先是上传时遇到“550 Permission denied”错误,根源在于配置文件中未开启写入权限。其次,启动时出现“500 OOPS: refusing to run with writable anonymous root inside chroot”的报错,这是一个安全限制,原因是FTP根目录对匿名用户拥有写权限,将其所属权改回root后问题解决。最后,上传的文件无法下载,通过调整`anon_umask`参数从默认的077改为022,赋予文件其他用户可读的权限,才得以解决。 作者在排查过程中参考了`man vsftpd.conf`手册,这对于理解配置项的含义和默认值非常有帮助。文中提供的最终配置文件也值得作为参考。这些从实际配置中总结出的经验,对于其他需要搭建类似FTP服务的运维人员来说,能直接避开常见的权限与安全配置陷阱。
FreeBSD常用的110条命令
这篇讲的是 FreeBSD 系统管理员和高级用户必备的“瑞士军刀”。作者将日常操作中最常用的 110 条命令进行了系统性的梳理,从系统状态监控、硬件与分区管理,到网络配置和软件安装,几乎覆盖了从开机到关机的所有关键操作环节。 文章并非零散的命令堆砌,而是构建了一个实用的排查与管理流程。例如,它详细说明了如何使用 `systat` 和 `netstat` 实时查看网络流量,如何通过 `vmstat` 和 `gstat` 深入分析内存与磁盘 I/O 状况。更重要的是,它直接切入了真实场景中令人头疼的问题——比如升级内核后无法启动、忘记 root 密码,或是系统断电后如何修复——并给出了一步步的解决方案,从进入单用户模式到使用 `fsck` 检查文件系统,操作路径清晰明确。 此外,文章也深入到软件生态的细节,不仅包含了 `ls`、`find` 等基础命令的进阶用法,还详细记录了从编译安装 Apache/PHP/MySQL 栈,到解决 XMMS 中文乱码、挂载 NTFS 分区等具体应用问题的过程。对于希望系统化掌握 FreeBSD 操作精髓的读者来说,这篇汇总无疑是一份可以直接对照执行的实用手册。
Linux修改用户密码-交互式与非交互式
这篇文章从实际运维需求出发,介绍了Linux系统中修改用户密码的几种实用方法。作者对比了交互式与非交互式操作的核心差异,并提供了可直接复用的代码示例。 对于交互式场景,文章以`passwd`命令为例,展示了手动输入新密码并确认的完整流程,适合单机或少量用户的操作。而针对需要脚本化、批量执行的运维任务,作者重点讲解了非交互式方案:使用`chpasswd`命令通过管道一次性传入`用户名:密码`对,或结合`passwd --stdin`重定向密码输入,这两种方法都无需人工干预,特别适合自动化部署。 文章进一步探讨了更灵活的`expect`脚本方案。该脚本能模拟交互式过程,自动响应密码提示并完成修改,解决了`passwd --stdin`在某些发行版中不可用的问题。作者还贴心地解释了脚本中TCL语法的巧妙之处,即利用反斜杠将注释延续到下一行,避免`exec`重复执行。 从简单的命令行操作到自动化的脚本实现,这篇文章覆盖了从手动到全自动的完整路径,为不同场景下的密码管理提供了清晰的选择依据。
awk调用shell,并将变量传递给shell
这篇讲的是在awk脚本中调用Shell并传递变量的一个具体技巧。作者从一个常见的开发场景切入:当awk处理流程需要借助外部Shell命令完成时,如何让Shell能“感知”到awk上下文中的变量。 文章聚焦于实现这一操作的核心函数`system()`,并指出了一个容易忽略但至关重要的语法细节:调用Shell脚本时,命令字符串的拼接需要特别注意空格的使用,正确的写法是`system("sh my.sh " $var)`。通过提供的简单示例,可以清晰看到变量是如何从awk环境传递到Shell脚本内部,并被正确处理的。 对于经常编写文本处理流水线或复杂运维脚本的开发者来说,掌握这种跨语言调用的变量传递方法,能极大增强脚本的灵活性和自动化能力,是提升工作效率的一个实用知识点。
Linux上删除空行的方法
处理文本数据时,清理空行是常见需求。这篇文章系统介绍了 Linux 下四种最常用的工具:grep、sed、awk 和 tr,它们都能轻松达成目标,但各有其巧妙的切入点。 作者没有止步于罗列命令,而是细致地指出了它们的关键差异。例如,`grep .` 和 `grep -v '^$'` 都能过滤空行;而 `sed '/^\\s*$/d'` 和 `awk NF` 则能更进一步,连只含空格、制表符等“空白内容”的行一并删去。这个细节在处理格式不规整的日志或配置文件时非常有用。 文章还特别提到了一个挺有意思的细节:在处理海量数据时,`grep .` 这种写法的执行效率通常比较高。这从侧面提醒我们,选择工具不仅要考虑功能是否满足,性能表现也是重要的考量因素。整体来看,文章通过具体的命令示例和对比,为读者提供了一个清晰实用的命令行工具选用指南。
查询Linux系统最后重启时间的三个方法
这篇讲的是如何在Linux系统中快速查明最后一次重启时间。作者没有停留在单纯介绍命令,而是梳理了三种不同思路的方法,并对比了它们的直接程度和适用场景。 最直接的是`who -b`,一条命令就能清晰看到系统启动的日期和时间。而`last reboot`则提供了更丰富的历史视角,它通过“reboot”这个伪用户的登录记录,不仅能看到最近一次重启,还能回溯过去多次的启动历史,方便进行时间线分析。 `uptime`虽然不直接显示启动时间点,但巧妙地利用了“当前时间”和“已运行时长”这两个信息。通过简单相减,我们就能推算出启动时刻。这更像是一个实用的逆向推算技巧。 文章的价值在于,它不仅仅给了你三个“答案”,更是呈现了三种不同的技术思路:直接查询、历史追溯与间接推算。无论是运维人员想快速获取信息,还是开发者需要理解系统行为,都能从中找到适合当下场景的解法。掌握这些基本命令,能帮你更高效地与系统“对话”,摸清它的运行状态。
Linux上的Shebang符号(#!)
这篇讲的是Linux和Unix系统里那个常见的符号“#!”。作者从它的名字“Shebang”说起,解释了这个名称其实来源于“SHArp”(#)和“bang”(!)的组合,还提到了Unix之父丹尼斯·里奇本人对命名的回忆,为这个技术细节增添了历史趣味。 文章的重点在于阐述这个符号的实际用途:它是脚本第一行的解释器指令,告诉系统该用哪个程序来执行这个文件。作者清晰地列出了几种常见情况:比如没有#!行时默认使用当前Shell;如果指定的解释器路径不存在或没有执行权限,系统会报出具体的错误信息;值得注意的是,#!后面必须写绝对路径,它不会去$PATH里自动查找。这些细节对于脚本编写和调试很有帮助。 最后,文章通过一个简单的“hello world”脚本示例,演示了从编写#!行、赋予执行权限到直接运行的完整过程,让抽象的概念变得具体可操作。对于刚接触Shell脚本或偶尔使用但想弄明白原理的开发者来说,这是一篇不错的速查小指南。