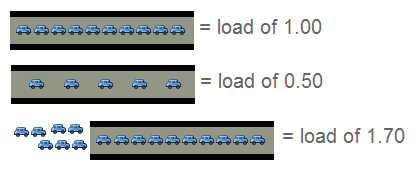
Linux系统Load average负载详细解释
这篇从 top 和 uptime 命令输出里的三个数字说起,详细拆解了 Linux 系统中一个最常见却也最容易被误解的指标——Load average。 文章核心厘清了一个关键认知:这三个数值并非直接的 CPU 使用率,而是系统处于“运行”和“不可中断睡眠”状态的平均进程数。作者强调,理解负载必须结合系统的 CPU 核心数,负载值为 N 并不直接代表 N 个 CPU 被占满。文章会具体解释,如何通过比较负载值与 CPU 核心数来判断系统是处于空闲、均衡还是过载状态。 此外,文章还剖析了一分钟、五分钟、十五分钟这三个时间窗口的意义。短时间的负载波动可能由瞬时任务引起,而持续较高的长时间平均负载则更可能预示着系统性能的持续瓶颈。这帮助运维人员区分偶发压力与持续性问题,从而做出更准确的判断。 对于常常看着这三个数字一头雾水的工程师来说,这篇文章提供了一套清晰的解读框架,帮助建立正确的系统负载观测思维。
ubuntu 笔记之:如何修改dns
这篇文章记录了一个实际问题:北京地区有用户发现其Ubuntu系统上网时,域名解析异常缓慢,ping网关延迟仅3毫秒,但解析一个域名却经常需要2秒以上。问题的根源被确认是运营商提供的DNS服务器不稳定。为了解决这个“抽风”的故障,作者着手修改了系统的DNS配置。文章具体分享了在Ubuntu(特别是使用NetworkManager管理网络)的环境下,如何通过修改系统配置文件来指定更可靠的DNS服务器地址。这是一个典型的因上游DNS服务问题导致的本地网络故障,解决方法直接有效,对于遇到类似网络卡顿的用户具有实操参考价值。
一个使用PC服务器的高可用性方案介绍
传统小型机加存储的架构成本高且扩展性有限,作者从硬件性能飞跃的角度提出了一种替代方案。他指出,凭借英特尔Nehalem处理器的强大性能和SSD硬盘的高IOPS,使用高性能PC服务器完全具备取代传统小型机的实力——以2009年发布的Nehalem为例,两颗四核CPU的性能已可媲美甚至超越同期中型小型机。存储方面,单块SLC SSD即可达到上万IOPS,通过多块SSD组成的阵列,其随机读写性能足以匹敌高端磁盘存储。 该方案的核心逻辑在于利用标准化、易扩展的PC硬件构建高可用集群,从而摆脱专用硬件的锁定。这不仅显著降低了硬件采购与维护成本,其横向扩展能力也更适合应对业务增长。作者用具体数据证明了PC服务器在计算与I/O两个关键维度上都已具备可行性,为追求性价比和弹性的企业提供了一条新的架构思路。
从磁盘映像中挂载或提取指定的 LVM 逻辑卷
这篇讲的是如何处理含有 LVM 分区的硬盘映像,具体是如何从中挂载或提取某一个逻辑卷(LV)。和直接按偏移地址挂载普通分区不同,LVM 的盘区(PE)分配机制导致逻辑卷在映像文件里往往是不连续的碎片,因此简单的偏移量法行不通。 文章的核心方案是,只要本地 Linux 系统安装了 LVM 支持,就可以完全借助 LVM 自带的实用工具来解决这个问题。作者延续了之前关于挂载磁盘映像中指定分区的思路,但将场景深入到了更复杂、也更常见的 LVM 层面,给出了一个清晰的操作路径。这本质上是利用 LVM 工具自身的扫描和激活能力,去识别并“连接”映像中分散的逻辑卷数据块,从而实现透明访问。
从磁盘映像中挂载或提取指定分区
作者在处理虚拟机磁盘映像时,遇到了一个常见需求:如何从磁盘镜像文件中直接挂载指定的分区到本地 Linux 文件系统,而不必提取整个镜像。这通常发生在需要快速检查或修改虚拟机中某个分区内容的场景下,比如进行系统维护或数据分析。 文章核心介绍了一种高效的方法:利用 mount 命令的偏移量参数来直接挂载。虽然传统做法是用 dd 工具将目标分区从磁盘映像中提取出来,然后再进行挂载,但作者指出 mount 本身支持针对 loop 设备设置偏移量,这能省去提取步骤,直接从原始映像文件中定位并挂载所需分区。具体来说,通过计算分区的起始扇区和扇区大小,结合偏移量选项,可以实现一键挂载,大大简化了操作流程。 这种方法在处理大型虚拟机映像时尤其有用,避免了冗余的磁盘读写,提升了工作效率。作者通过实际笔记形式,将这一技术点清晰呈现,强调了其便捷性和实用性,为类似场景下的技术操作提供了一个直接可行的解决方案。
如何快速搭建一个VPN(pptp)
这篇讲的是如何在一台Debian VPS上快速搭建基于PPTP协议的VPN服务器。作者从一台具体的硬件环境出发——一台运行Debian GNU/Linux 5.0、物理位置在加州弗里蒙特的VPS,演示了整个安装流程。 教程的核心在于“快速”和“可用”。作者没有纠缠于复杂的网络理论或VPN的日常使用,而是直奔主题,使用apt-get命令安装pptpd软件包,并给出了其他Linux发行版的通用适配思路。整个过程被精简为几个关键步骤,旨在让读者能立刻动手实践,快速获得一个可用的VPN服务。 虽然篇幅简短,但文章明确区分了“搭建”与“使用”这两个阶段,将焦点牢牢锁定在服务器端的部署上。它面向的读者应该是有一定Linux命令行基础、急需一个简易点对点隧道方案的用户。教程的实用性正体现在这种不绕弯子的直接性上。
Ubuntu 9.04 用 iBus pinyin 替换scim
这篇讲的是作者在使用Ubuntu 9.04时,对默认的SCIM输入法框架下的智能拼音功能感到失望,认为其词库和智能程度不足。为了解决这个日常使用中的痛点,作者尝试换用当时口碑较好的iBus Pinyin输入法。 文章具体说明了从SCIM切换到iBus Pinyin的动机与过程。核心在于对比两者在拼音输入体验上的差异,尤其是在词库更新、联想功能和整体流畅度方面。作者通过实际的替换操作,验证了新方案能否带来更顺畅、更符合个人习惯的中文输入体验。 最终,作者确认iBus Pinyin成功提升了输入效率,解决了此前“傻呼呼”的编码问题。对于同样使用旧版Ubuntu并对默认输入法不满意的用户,这篇短文提供了一个简单有效的优化思路:更换输入法框架及其拼音引擎,就能直接改善日常操作的舒适度。
我和Linux
这是一篇个人经历复盘文章。作者从响应社区号召出发,分享了自己与Linux结缘并深入“折腾”的整个过程。 这篇内容没有聚焦于某一个具体的技术难题,而是以时间为线,串起了一个爱好者从初识Linux,到为了用上它而折腾双系统安装,再到为追求更好体验而动手配置桌面环境、编译内核与软件的完整历程。文章记录了其中遇到的驱动不兼容、环境配置失败等经典“坑”,也分享了问题解决后那份独有的成就感。 作者想传递的核心观点很明确:Linux的魅力不仅在于其强大的系统本身,更在于这个由无数次“折腾”构成的学习与探索过程。每一次手动修复,都是对系统原理的一次深入理解。文中那些看似琐碎的故障与解决方案,共同构成了一幅生动的实践地图,为同样想入门或正在进阶的读者提供了真实的参考和鼓励——在Linux的世界里,动手试错本身就是最好的老师。
服务器中swap 的划分
这篇讲的是服务器环境中swap空间的规划与划分,内容源自RHEL的官方文档,针对性很强。作者从Linux内存管理机制出发,重点解释了在服务器场景下,为何不能简单地“关闭swap”或“设得越大越好”。 文章的核心在于对比不同配置策略的利弊:比如,将swap作为内存溢出的“安全网”时,应该预留多少空间才合适?如果追求高性能,又该如何通过调整swappiness参数来减少对swap的依赖?这些讨论都紧扣“服务器”这一前提,区分了与桌面环境的不同考量。 它没有停留在理论层面,而是给出了具体的配置建议和考量维度,帮助管理员根据服务器的内存大小、负载类型(如内存敏感型应用)做出权衡。对于需要部署关键业务的运维人员来说,这是一份清晰、实用的配置参考指南。
linux把文件压缩成.tar.gz的命令
这篇讲的是 Linux 下最常用的压缩格式 .tar.gz 的具体操作方法。 文章从最基础的 .tar 归档格式讲起,重点演示了如何通过 `tar` 命令配合 `-z` 参数来创建 .tar.gz 压缩包。作者详细拆解了命令的各个选项,比如 `-c` 创建、`-v` 显示过程、`-f` 指定文件名,并结合实例展示了一行命令如何完成“打包并压缩”的动作。 除了基本操作,文章可能还对比了其他常见压缩工具(如 bzip2 或 xz)与 .tar.gz 的差异。这些工具在压缩比和压缩速度上各有侧重:gzip 处理速度快、兼容性好,而 xz 通常能提供更高的压缩率,但耗时更长。这种对比帮助读者在日常运维或开发中,能根据对文件大小或处理速度的具体要求来做出合适的选择。 读者能快速掌握创建、查看和解压 .tar.gz 文件的核心命令,理解不同压缩选项背后的权衡,从而更高效地管理文件。
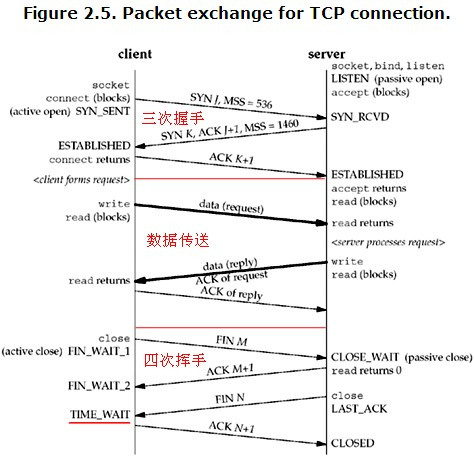
用netstat查看网络状态详解
这篇详细拆解了用netstat命令查看网络状态的完整方法。文章开篇就直指核心,系统梳理了Linux服务器上最常遇到的11种网络连接状态,从最经典的ESTABLISHED、TIME_WAIT到相对冷门的CLOSING状态,每一种都结合了实际场景说明其含义与影响。特别结合了TCP状态机图解,帮助读者从底层理解这些状态是如何流转与变迁的。 作者没有停留在理论层面,而是给出了一系列实用的排查思路和命令组合。比如如何快速过滤出大量处于特定状态的连接,或者通过计数发现潜在的连接泄漏或性能瓶颈。这种从原理到实践的讲解方式,让读者不仅能“看懂”状态,更会“用好”netstat来诊断问题,比如定位连接数异常、排查服务无响应或优化高并发下的网络配置。 对于后端开发、运维工程师来说,这是一份清晰的排查手册,让读者在面对复杂的网络问题时,能够有章可循地快速定位。
tomcat catalina.out日志切割每天生成一个文件
这篇讲的是如何解决 Tomcat 的 catalina.out 日志文件无限增长的问题。文件过大会影响服务器性能,因此需要自动切割并清理旧日志。 文章作者的实践过程很有趣,展示了一个方案如何被逐步修正和完善。最初提出的脚本思路是直接复制并清空 catalina.out,但这种方法被指出是无效的——因为 Tomcat 进程保持着文件句柄,单纯清空文件后,新日志并不会写入新的切割文件中。一个更“暴力”但直接的方法是停止 Tomcat、重命名日志文件再启动,不过这带来了服务中断的代价。 最终,文章推荐了一个更优雅的方案:利用 cronolog 这个日志切割工具。通过修改 Tomcat 的启动脚本,让其输出的日志通过管道直接由 cronolog 处理,就能实现按日期(如 catalina.2023-10-27.out)自动生成日志文件。这个方案无需重启服务,也无需复杂的脚本,是更符合生产环境要求的做法。 整个过程从踩坑到寻找更优解,很实际地展示了在运维工作中如何为一个常见问题找到可靠且高效的解决方案。
利用taskset有效控制cpu资源
这篇讲的是如何在一台同时运行多个关键服务的服务器上,解决备份压缩、网络传输等后台任务挤占CPU资源的问题。作者从一个常见的实际场景出发——有限的物理核心上混部服务,互相抢夺计算资源导致性能抖动。核心方案是利用Linux自带的taskset工具,为不同服务绑定独立的CPU核心(即设置CPU亲和性),从而在硬件层面隔离资源,无需部署复杂的调度器。 文章具体演示了如何通过taskset命令或systemd配置,将数据库、应用服务等关键进程固定到特定核心,将备份、压缩等CPU密集型批处理任务限制到其余核心上运行。这种轻量级的隔离手段能立刻缓解资源争抢,确保前台服务的响应稳定性。结论是,对于资源紧张但又需要兼顾多种任务的单机环境,通过taskset进行CPU绑定是一种简单高效、立竿见影的优化手段。
在Centos(RHEL)上安装和配置MRTG
这篇讲的是在CentOS(或RHEL)系统上安装与配置MRTG的实践经验。作者开门见山地指出,MRTG作为一个经典工具,在如今普遍使用RRDtool或Cacti的环境中已显得“过时”。然而,他依然选择了MRTG,给出了三个非常具体且务实的理由。 文章没有停留在工具的新旧争论上,而是深入对比了MRTG与RRDtool、Cacti在部署复杂度、资源占用和特定场景适用性上的差异。核心观点是:对于需要快速部署、监控规模不大、且对系统资源消耗敏感的环境,MRTG的简洁性和低门槛反而成为优势。作者详细演示了在CentOS上的安装步骤,并分享了如何通过优化配置文件来提升其监控效率和稳定性。 对于那些正在寻找轻量级、开箱即用的网络设备流量监控方案,或者对现代工具的复杂配置感到头疼的运维人员来说,这篇文章提供了一个清晰的回退选项和完整的实施路径。
perl打包的建议
这篇讲的是作者为一个需要部署到公司数千台服务器的Perl程序做上线准备的经历。尽管在开发阶段进行了无数次测试,作者依然坚持在最后关头将程序做成rpm包,并在生产环境中进行验证。结果,这一谨慎的举动果然发现了打包后引入的、仅在真实环境下才暴露的小问题,所幸最终所有测试均顺利完成。 文章的核心观点非常清晰:在复杂的企业级部署场景中,无论前期测试多么充分,最终的线上环境验证都是一个不可省略的关键步骤。它强调了理论环境与真实生产环境之间可能存在的微妙差异,而一个最终的、贴近实际运行条件的测试,往往是捕获这些“意外”的最后一道有效防线。作者用亲身经历提醒同行,对于关键系统的上线,耐心和坚持完成所有验证环节,是规避风险的务实之道。
perl更新/修改/删除文本文件内容
这篇讲的是如何用Perl高效地更新、修改和删除文本文件中的内容。文章从实际的脚本操作出发,聚焦于几种核心方法。其中重点介绍了“脚本更新”这一途径,具体展示了如何利用Perl的文件处理能力和正则表达式,直接定位并修改文件中的特定字符串或模式匹配到的段落。这不仅包括单个文件的精准替换,也涵盖了批量处理多个文件的技巧,对于需要维护日志、配置文件或进行数据清洗的开发者而言,提供了非常直接的解决方案。文章的对比视角体现在对不同操作场景的区分上:如果是简单字符串替换,直接读写文件即可;若涉及复杂模式匹配与多处修改,则更依赖强大的正则表达式引擎。这种从具体语法到应用场景的梳理,让读者能快速判断在自己的任务中该如何选择最合适的Perl文本处理方式。
利用for + grep awk 解决grep + xargs
这篇讲的是如何用更稳妥的方式在Shell中批量搜索文件。作者从常见的“cat aaa | xargs grep **”这个命令组合出发,指出了它潜在的一个痛点:当文件列表(aaa文件)中的文件名包含空格、换行符等特殊字符时,xargs可能会错误地切割参数,导致命令执行失败或结果不符预期。 文章提出,通过一个简单的`for`循环结合`grep`和`awk`,可以构建一个更健壮的替代方案。具体做法是用`while read`逐行读取文件列表,然后在循环体中用`grep`处理每个文件,并用`awk`进行后续的过滤或格式化。这种方式彻底避免了xargs解析参数时可能引发的歧义,能可靠地处理各种“古怪”的文件名。 作者也对比了两者:xargs方案简洁、高效,适合处理文件名规范的常规场景;而for循环方案虽然语法稍多一步,但可靠性高,尤其适合处理来源复杂、文件名不可控的文件列表。文章没有停留在单纯替换,而是清晰地划出了各自的最佳适用范围。
netstat和web主机socket文件分析
这篇讲的是如何通过netstat命令和系统socket文件来分析Web主机的网络状态。作者从一次服务器响应变慢的实际排查经历出发,详细展示了在Linux环境下,如何使用netstat -tunlp快速列出所有监听端口及对应进程,并重点解读了ESTABLISHED、TIME_WAIT等关键状态连接数的含义。文章还进一步带读者进入/var/run/目录,分析了像nginx、mysql这类服务生成的sock文件,解释了Unix domain socket与网络socket的区别及其在进程间高效通信中的应用场景。 通过对比netstat提供的实时网络连接视图与socket文件揭示的进程间通信路径,文章清晰地勾勒出排查Web服务端口冲突、连接泄漏或进程僵死等问题的具体步骤。例如,当发现某个端口被意外占用,或大量TIME_WAIT堆积时,如何定位到具体的进程ID并采取相应措施。这种将标准命令行工具与底层文件系统观察相结合的思路,为系统管理员和后端开发者提供了一套实用且深入的诊断方法论。
Linux下常用压缩格式的压缩与解压方法
这篇实用的指南详细梳理了Linux系统下多种主流压缩格式的操作命令,帮助开发者快速查阅。文章将.tar、.gz、.tar.gz、.bz2、.tar.bz2、.zip、.rar等格式并列,清晰地展示了每种格式对应的解压和压缩命令,特别区分了打包(如tar)与压缩(如gzip)的概念差异。 关键差异一目了然:例如,.tar.gz格式结合了打包与压缩,使用tar命令并加z参数处理;而.zip和.rar作为跨平台常用格式,命令相对独立,其中.rar还需额外安装工具。文章还坦诚指出了某些格式(如.tgz、.bz)在压缩方法上的“未知”状态,信息真实。 这份清单覆盖了从传统的.Z到流行的.rar等多种场景,无论是处理单个文件还是整个目录,读者都能根据文件后缀迅速定位到正确命令,避免了在碎片化信息中反复查找的麻烦。
Centos挂载新硬盘开机自动挂载
这篇教程讲的是在CentOS系统中,如何让新加入的硬盘不仅成功挂载,还能在系统重启后自动就位,省去每次都要手动操作的麻烦。 作者从一个常见的运维场景出发:为服务器物理添加或虚拟机新增了一块硬盘后,系统虽然能识别出来,但默认情况下重启就会“忘记”它。文章先带读者快速认识Linux下硬盘的命名规则(比如sda、hda),并用`fdisk -l`命令确认系统是否看到了新硬件。 核心方案围绕修改系统配置文件来实现自动挂载。教程清晰地梳理了关键步骤:先用`fdisk`或`parted`创建分区,再用`mkfs`格式化,接着通过`mount`命令手动挂载一次进行测试。最关键的一步,是编辑`/etc/fstab`文件,将新硬盘的挂载信息(如设备路径、挂载点、文件系统类型、参数)写入其中。文章很可能还提醒了读者在操作前做好数据备份、核对UUID以防设备名变化等实用注意事项。 对于经常管理Linux服务器的用户来说,这篇内容直接解决了硬盘扩容后的一个基础但重要的配置问题,确保了存储空间能够持久、稳定地被系统所用。