如何使用Shell缉拿问题进程
服务器在凌晨某时段突发高负载,但人工排查时故障往往已消失,成为许多运维人员的棘手难题。文章作者面对这一挑战,没有依赖复杂的监控体系,而是用一段简洁的Shell脚本巧妙“伏击”了问题进程。 核心思路是利用Cron定时任务每分钟运行一个脚本,实时读取系统负载。一旦发现平均负载超过CPU核心数,便立即通过`ps`命令捕获当前所有进程的快照并存档。这样,当次日早上分析日志时,就能直接从保存的文件里看到案发时的“进程嫌疑人”。 作者特别提醒了实际使用的两个关键点:一是要注意定期清理日志文件,避免占满磁盘;二是Cron的分钟级粒度可能漏掉更短暂的峰值,对精度要求高的场景可改为常驻守护进程。虽然脚本本身并不复杂,但它将被动响应转化为主动记录,有效解决了故障排查中“抓不到现行”的核心痛点,体现了运维中用简单工具解决实际问题的实用智慧。
CentOS修改用户最大进程数
这篇讲的是 CentOS 系统中调整用户最大进程数时一个容易被忽略的“坑”。通常大家都会在 `/etc/security/limits.conf` 里配置 `noproc` 参数,期望以此限制或放宽用户进程数。但在实际操作中,尤其是在 CentOS 6.3 等一些旧版本上,你可能会发现按常规方法修改后配置完全不生效。 问题的根因在于,系统默认会先读取 `/etc/security/limits.d/` 目录下的配置文件,而其中的 `90-nproc.conf` 文件同样定义了 `noproc` 限制,它的优先级更高,直接覆盖了 `limits.conf` 中的设置。因此,单纯修改 `limits.conf` 看起来就像是无效操作。 解决方法很直接:不再纠结于 `limits.conf`,而是去编辑那个真正起作用的 `/etc/security/limits.d/90-nproc.conf` 文件。将你期望的 `noproc` 值写入该文件保存,之后重启服务器服务即可生效。文章简洁地指出了这个特定环境下的配置优先级问题,帮助读者避开配置不生效的困惑,快速定位到正确的配置文件。
CentOS配置时间同步NTP
这篇讲的是在CentOS系统上配置NTP时间同步的实践指南。作者从生产环境时间准确性的重要性切入,明确指出应使用ntpd服务实现渐进式时间校准,而非可能导致数据库写入错误的ntpdate断点更新。 文章系统梳理了NTP的工作原理,包括服务器与客户端基于UDP 123端口的通信过程。随后详细列举了系统内与时间相关的关键配置文件(如/etc/ntp.conf、/etc/localtime)和常用命令(如date、hwclock、ntptrace)。在核心的安装配置部分,提供了完整的时区设置、服务安装步骤,并重点解析了ntp.conf文件中关于访问限制、上级服务器列表以及时钟源配置的具体含义。 为帮助读者验证成果,文中说明了如何通过ntpstat、ntpq -p等命令检查同步状态与服务器连通性,也提到了初次启动可能需要数分钟等待连接这一常见现象。最后,作者附带了国内主要城市的NTP服务器地址资源。
大分区使用xfs文件系统存储备份遇到的问题
这篇讲的是一个在24TB大分区上使用XFS文件系统做备份时,遇到的典型“陷阱”。同事反馈明明磁盘显示还有2.4TB可用空间,inode使用率也极低,系统却突然报告没有磁盘空间了。 经过排查,根因藏在XFS的一个默认设计里:在32位inode模式下,XFS会将所有inode(文件元数据)集中在磁盘最开始的1TB空间内。当这个1TB区域因存放了大量小文件的inode而“填满”时,即使磁盘其余部分空空如也,系统也无法创建新文件,从而抛出令人困惑的“磁盘已满”错误。 文章给出的解决方案明确而直接:在挂载文件系统时,加上`inode64`选项。这个选项会让inode和数据块就近存放,打破了最初的1TB限制,完美适配超过1TB的大容量磁盘。文末还贴心地提醒,如果磁盘本身就小于1TB,则无需担心这个问题。对于运维和架构人员来说,这是一个在规划大容量存储时非常值得留意的细节。
AWK 简明教程
这是一篇关于Linux文本处理工具AWK的入门教程。作者从AWK的历史讲起——这个由贝尔实验室三位大佬(姓氏首字母为A、W、K)于1977年创造的“上古神器”,并以一篇《Linux下应该知道的技巧》引发读者兴趣为引子。 教程风格极为直接,作者自述“基本无废话”,目的有二:让你在通勤或如厕的碎片时间里就能读完;更希望像一个火辣的引子,激发你自己动手深入研究的兴趣。全文通过大量实例展开,比如从`netstat`的输出文件中提取特定列(`$1,$4`)、使用`printf`进行格式化输出,以及如何添加过滤条件(如`$3==0 && $6=="LISTEN"`)来筛选出所需的网络连接记录。 教程从最简单的列提取,逐步过渡到过滤、格式化等核心操作,通过真实的网络状态数据作为案例,让读者能直观地看到AWK处理文本的威力。它没有试图面面俱到,而是聚焦于最常用、最高效的操作模式,目标是让你快速上手,掌握用AWK高效处理日常文本流的实用技能。

Linux常用系统信息查看命令
这篇文章整理了Linux运维和开发中常用的系统信息查看命令,相当于一份精炼的“系统侦察”手册。 它从“系统”、“资源”、“磁盘和分区”、“网络”、“进程”、“用户”、“服务”和“程序”这八个维度,系统地罗列了对应的命令行工具。比如,想知道系统基本情况,可以运行 `uname -a` 查看内核版本,用 `free -m` 瞬间看清内存使用;排查网络问题时,`ifconfig`、`netstat` 和 `iptables` 就是标准三件套;而 `ps -ef` 和 `top` 则是进程监控的常用起点。 文章最大的特点是实用和直接。它没有展开讲解每个命令的复杂参数,而是聚焦于“用哪个命令看什么”这个核心场景,让读者能快速对照自己的需求找到对应的入口。无论是新手想快速了解服务器状态,还是老手需要备忘某些不常用的命令(比如 `hdparm` 查看磁盘参数,或 `dmesg | grep IDE` 查看启动日志),这份清单都提供了清晰的指引。 这份清单像一张系统的“体检项目单”,把散落在各处的查看命令按用途归类,方便你随时取用,对日常的服务器管理和问题排查很有帮助。
深度剖析告诉你irqbalance有用吗?
这篇深度技术剖析探讨了irqbalance这个中断平衡守护进程的实际价值。文章从“是否有必要开启它”这一实际运维问题切入,通过解读源码揭示了irqbalance的工作机制:它每10秒循环收集/proc/interrupts的中断分布数据,并根据设备类型(如网卡、存储设备)与CPU拓扑结构,动态计算并调整中断的CPU亲缘性。 作者指出,在特定高性能场景下(如应用已绑定CPU核),irqbalance的自动调整可能并非最优甚至不必要,因此需要理解其原理来做出正确取舍。文章深入解析了irqbalance如何利用SMP Affinity接口、区分中断类型在Package、Cache或Core级别进行平衡,将原本黑盒的守护进程逻辑清晰展现出来。对于需要精细调优系统中断分布的工程师而言,这些底层细节是做出判断的关键依据。
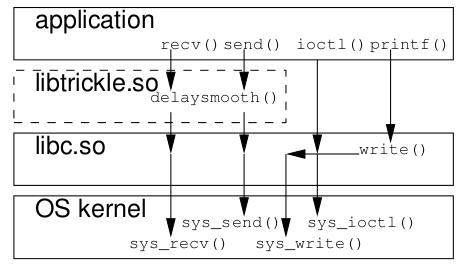
限制单个进程的带宽
这篇文章讲的是如何在Linux系统中限制单个进程的网络带宽,而非传统的端口或全局限速。作者从系统管理员常见的需求出发,对比了几种方案的可行性。 传统的iptables配合owner模块的方法,在现代支持SMP的内核中已因匹配项被移除而基本失效。文章接着推荐了一个名为trickle的工具,它通过ELF preloader机制替换socket库函数来实现限速,用法简单。但作者也明确指出其局限:对静态编译或suid权限的程序无效。 为了解决更复杂的场景——例如对已运行进程动态调整带宽——文章最终引入了cgroup的net_cls控制器。它通过给数据包打标记,再交由tc流量控制工具处理,实现了类似iptables但更灵活、更现代的管理方式。这篇文章为不同环境下的进程带宽限制需求,提供了从传统工具到内核级方案的清晰对比和选型思路。
Linux 找出大文件汇总
这篇讲的是 Linux 系统管理中一个非常实用的技巧:如何快速定位那些占用大量磁盘空间的“罪魁祸首”文件。作者没有停留在单一的命令上,而是横向对比了多种主流工具和方法,堪称一份“找出大文件”的工具箱。 核心部分详细对比了 `find` 命令在 RedHat 系和 Debian 系中的细微差异,比如 `awk` 提取的字段编号不同,这种细节对新手很友好。除了 `find`,文章还扩展介绍了使用 `ls -lS` 按大小排序、用 `du` 配合 `sort` 和一个精巧的 Perl 脚本来可视化目录占用情况(用星号条形图直观显示)。 特别值得注意的是,文章不仅教你怎么“找大”,也提到了如何“找小”,并且提供了不跨文件系统查找(`-xdev`)等实用选项。整体来看,这是一篇非常扎实的速查手册,能帮你在磁盘空间告急时,快速掌握从基础到进阶的多种排查手段。
Travis CI:专为开源项目打造的持续集成环境
这篇讲的是如何为GitHub上的开源项目接入Travis CI持续集成环境。作者以Java项目Moco为例,详细演示了从创建配置文件到最终在README中添加状态标识的全流程。 核心步骤非常清晰:首先在项目根目录添加`.travis.yml`文件,指定语言(如java)和需要测试的JDK版本(如Oracle JDK 7和OpenJDK 6/7)。Travis CI会自动识别如Gradle这样的构建工具,并执行标准的检查任务。接着,用GitHub账号登录Travis CI并同步项目,开启对应项目的构建钩子。这样,每次提交代码到GitHub,Travis CI就会自动在多个JDK环境下运行测试,确保兼容性。 文章还指出了一个实用技巧:可以在项目的README文件中嵌入Travis CI的构建状态徽章,让其他开发者一目了然地看到项目的构建状态。对于使用标准工具链的项目来说,整个配置过程确实“简单得一塌糊涂”,是开源项目实现自动化测试与集成的一个高效选择。
linux下搜索find命令详解
这篇文章来自一次内部技术培训,作者觉得分享的内容不够全面,于是系统地整理了 Linux 下 `find` 命令的各种常用选项和示例。 它开篇点明 `find` 是一个强大但速度较慢的搜索工具,随后围绕其基本语法 `find [路径] <表达式> [操作]`,详细拆解了十多个核心选项。文章不仅列举了按文件名(`-name`)、按时间(`-atime`, `-mmin`)、按用户(`-user`)和按大小(`-size`)进行查找的常规操作,还介绍了一些实用的进阶技巧。例如,使用 `-exec` 可以直接对查找结果执行命令,像批量删除 `.svn` 目录;利用 `-perm` 和 `-regex` 则能满足更精细的权限或模式匹配需求。文末附带的逻辑组合(`-o`, `-a`, `!`)和目录深度控制(`-maxdepth`)示例,让复杂条件的查询成为可能。 整体来看,这更像一份为团队定制的 `find` 命令速查手册,将零散的知识点梳理成了清晰的条目,每个选项都配以实际可运行的命令。对于日常需要在 Linux 文件系统中定位文件的开发者和运维人员来说,这份清单覆盖了绝大多数使用场景,省去了反复查阅手册的麻烦。
在移动硬盘上安装 Arch Linux
这篇讲的是作者如何在移动硬盘上搭建一个便携的 Arch Linux 学习环境。起因是厌倦了 Ubuntu 半年一次的大版本升级,同时希望深入接触滚动更新的发行版。为了不影响主力工作机,作者选择将系统安装在移动硬盘上,以便随时折腾和学习。 文章详细记录了从分区规划到系统配置的全过程。作者为这块硬盘设计了四个分区:10G 的 btrfs 分区安装 Arch 系统本身,10G 的 ext4 分区用作用户主目录,一个大容量 NTFS 分区用于日常数据交换,以及小容量的交换分区。安装过程中,他特别注意了针对移动存储设备的优化,比如在 fstab 中启用 relatime 和 discard 参数,将 /tmp 挂载到内存,并通过调整 swappiness 参数尽量减少对磁盘的写入,以保护硬盘寿命。 除了基础系统安装,文章也涵盖了引导配置、时区语言设置等初始工作。整个过程不仅是技术步骤的罗列,更分享了作者从 Ubuntu 转向 Arch 的心路历程,以及他对服务器环境稳定性的谨慎态度。对于想尝试新发行版又担心影响现有系统的读者来说,这提供了一个清晰的、可复现的实践路径。
应该知道的Linux技巧
这篇讲的是每个Linux用户都应该知道的效率技巧,核心观点直接而有力:在Unix/Linux下,最高效的技巧不是操作图形界面,而是掌握命令行,因为它意味着自动化。 文章从Quora的一个热门问答出发,结合作者的实践理解,梳理了一份从基础到进阶的实用清单。基础部分强调了学习Bash、vim和ssh的重要性,指出这些是高效操作的基石。日常技巧则聚焦于能立刻提升操作速度的快捷键与命令,例如用Ctrl-R历史搜索、用xargs串联命令,或是通过pstree和pkill管理进程。 清单中也不乏一些精妙的“冷知识”,比如利用`<(command)`将命令输出当作文件进行比较,或是通过`set -x`和`trap`调试与控制脚本。这些细节让自动化和脚本编写变得更灵活可靠。作者还不忘提醒,掌握man、Google搜索以及从源码编译,是自主解决问题和深入探索的关键。整篇文章罗列了数十个具体命令和场景,目的不是让你全部记住,而是展示命令行的丰富可能性——熟悉其中一部分,就能让你从繁重的手动操作中解脱出来,把时间留给更重要的思考。
Ubuntu Server清理无用内核
这篇文章解决的是Ubuntu Server在多次系统升级后,旧内核包(headers和image文件)累积占用磁盘空间的问题。作者直接给出了具体的清理步骤和命令。 方法首先通过 `dpkg --get-selections|grep linux` 命令列出所有与Linux内核相关的已安装软件包,让你清楚地看到哪些旧版本的内核headers和镜像文件仍然存在。接着,文章演示了如何使用 `sudo apt-get remove` 命令,针对每一个不再需要的旧内核版本(例如3.5.0-17和3.5.0-19),分别移除其对应的headers和image包。 在执行完清理命令后,文章再次运行查看命令进行验证。结果显示,之前状态为“install”的旧内核包已变为“deinstall”(卸载),而当前使用的内核版本(3.5.0-21)及其相关组件则保持“install”状态。整个过程清晰明了,从发现问题、执行操作到验证结果,形成了一个完整的操作闭环。 这篇文章的价值在于提供了明确的步骤和验证方法,对于需要手动管理内核、优化服务器存储的系统管理员来说,是一个非常实用的参考。
用msmtp代替系统自身的sendmail
系统自带的sendmail因为漏洞多、配置复杂,常被管理员禁用,但这会导致cron任务出错时无法及时知晓。作者为了解决这个问题,放弃了之前使用的但已停止维护的ssmtp,转而寻找并采用了msmtp作为轻量级替代方案。 文章详细分享了从安装、配置到与系统深度集成的完整步骤。关键不仅在于如何配置msmtp连接邮件服务器,更在于两个精妙的实践:一是修改`/etc/mail.rc`让系统`mail`命令默认使用msmtp;二是在crond配置中为`CRONDARGS`参数正确添加了`-t`选项。 作者特别指出,这个`-t`参数至关重要,它确保msmtp从标准输入读取收件人列表。此前遗漏此参数导致了cron任务虽然输出了日志但邮件发送状态异常的诡异问题。这个解决方案是作者在实际踩坑后总结出的独家经验。通过这一套替换,既保留了系统邮件通知的能力,又极大地简化了管理负担。
通过blktrace, debugfs分析磁盘IO
这篇讲的是当磁盘利用率飙到100%、程序变卡时,如何揪出背后的“元凶”文件。作者从实际场景出发,演示了如何组合使用blktrace和debugfs这两个工具,层层追查IO的来源。 具体来说,当iostat显示磁盘压力巨大时,先用blktrace捕获块设备层的IO请求。关键点在于grep出以“A”开头的日志行,这里是原始请求的入口,能清晰看到读写操作对应的源设备扇区。接着,通过debugfs的“icheck”命令,根据扇区号换算出的文件系统块号,反查到对应的inode号。最后,用“ncheck”命令把这个inode号映射为具体的文件路径——比如例子中的“test_file”。 整个流程就像顺藤摸瓜:从设备层的扇区,到文件系统的块和inode,最终定位到用户可见的文件。拿到这个结果后,就能结合自己的应用程序,分析为什么这个文件会被频繁读写,从而进行优化。文章给出了完整的命令示例和输出解读,实操性很强。
linux目录跳转快捷方式——z武器
这篇讲的是Linux下如何告别繁琐的`cd`命令,实现目录的“智能跳转”。作者从在机房目睹资深工程师行云流水般的`cd`操作说起,分享了自己想提升效率却常被“忘记目标目录在哪一层”困扰的经历,从而引出了一个名为“z”的命令行小工具。 z本质上是一个轻量的shell脚本,它通过自动记录你常访问的目录路径,让你只需输入目录名称的关键词就能一键跳转。文章清晰地介绍了它的核心用法:安装后,z会默默记住你的操作习惯。以后,无论你身处何处,只需输入`z 关键词`(例如`z python`),就能立刻进入之前记录过的、包含该关键词的目录,彻底省去了层层递进的`cd`和反复`Tab`补全的麻烦。 对于需要在多个项目目录间频繁切换的开发者和运维人员来说,这个小工具能显著提升命令行操作的流畅度与效率,是一个即学即用的实用技巧。
GTD时间管理
这篇讲的是作者如何从自己“忙到脑子不好用”的日常出发,借助GTD(Getting Things Done)理念和一款叫Remember The Milk的工具,重新夺回生活与工作的控制权。 作者面临的困境很典型:邮件堆积、任务优先级模糊,加上采用Sprint式的项目管理,每小时都需安排任务,压力之下难免感到“被剥削”。他提出的解法核心在于两点:一是建立条理,二是借助工具。 在方法论上,他提炼出GTD的几个关键实践:两分钟内能完成的事立刻去做;按“紧急性”与“重要性”将任务划入四个象限,重点警惕“紧急但不重要”的事务陷阱;通过持续回顾来积累智慧。工具选择上,他推荐了免费功能丰富的Remember The Milk,特别点出了其“双坐标”(列表与关键字)分类、通过“smart add”快速定义任务属性,以及方便的提醒和周计划视图等特色功能,甚至支持好友间互派任务与手机同步。 文章并非空谈理论,而是从个人痛点切入,将抽象的时间管理原则与具体的软件操作细节相结合,最后落脚于“轻松一点,快乐工作”的实在祝愿,为同样在效率迷宫中挣扎的读者提供了一份可操作的指南。
你应该知道的16个Linux服务器监控命令
这篇讲的是Linux系统管理员必备的16个服务器监控命令。作者从追求最佳服务器性能的角度出发,强调了相比于GUI工具,命令行监控能更精准地洞察系统内部的真实状况。文章开篇就建议将服务器设置为运行级别3(纯命令行模式),以减少不必要的资源消耗。 随后,文章逐一介绍了从iostat、mpstat到netstat、top等16个核心命令。每个命令都附带了具体的用法示例和输出解读,例如用iostat快速定位潜在的IO瓶颈,通过free -m查看内存概况,使用mpstat分析多核CPU负载,以及利用netstat诊断网络连接状态。这不仅是一份命令清单,更是一套组合拳,帮助管理员全面掌握CPU、内存、磁盘IO和网络等关键指标的实际状况。 值得注意的是,文章没有停留在基础命令的罗列,还提及了如nmon这样集成了多种监控视图的工具,并说明了pmap、strace等用于深入排查特定进程问题的命令。对于希望从“救火队员”转变为能提前预见并解决问题的专业运维人员,这些基于命令行的监控技巧正是其核心能力所在。
Web工程师的工具箱
这篇文章整理了一份涵盖开发、测试、调试与文档等环节的Web工程师在线工具集合。它并非简单罗列,而是将功能相近的工具进行了分组介绍,方便读者按需查找。 比如,用于发送和检查HTTP请求的工具有RequestBin、Hurl和Httpbin,它们都能帮助开发者直观地分析网络交互;而用于检测网站状态、性能或安全性的工具则包含了Host tracker、SSL Checker和Loadzen等。文章特别指出,这份清单比常见的“18款工具”版本更为完整,补充了评论区和后续更新中的工具,总数达到40余个,像用于模拟网络问题的Necrohost、将HTML转为API的Apify,以及在线代码编辑器JSFiddle等都能找到。 这份“工具箱”的价值在于,它将分散的、实用的在线工具系统地汇总在一起,让工程师无需费力搜集,就能快速定位到解决特定问题的利器,从而提升开发调试的效率。
